I Built a Knowledge Base That Writes Itself. Here Is What Andrej Karpathy Got Right.
Andrej Karpathy posted about using LLMs to build personal knowledge bases. I took his workflow, wired it into my Obsidian vault with Claude Code, and within an hour had 21 cross-linked wiki articles compiled from YouTube transcripts. Here is how it works and why it matters.
TL;DR
Andrej Karpathy tweeted about using LLMs to build personal knowledge bases — raw sources in, compiled wiki out, all in Obsidian. I implemented his entire workflow in one session using Claude Code skills. Four YouTube transcripts became 21 cross-linked wiki articles. The system now compiles new sources, health-checks its own consistency, and searches itself. It took an afternoon. It will compound forever.
Your AI should not just answer questions. It should build a knowledge base that makes every future question easier to answer.
The Tweet That Started This
On Easter weekend, I was catching up on my feed and saw this post from Andrej Karpathy:
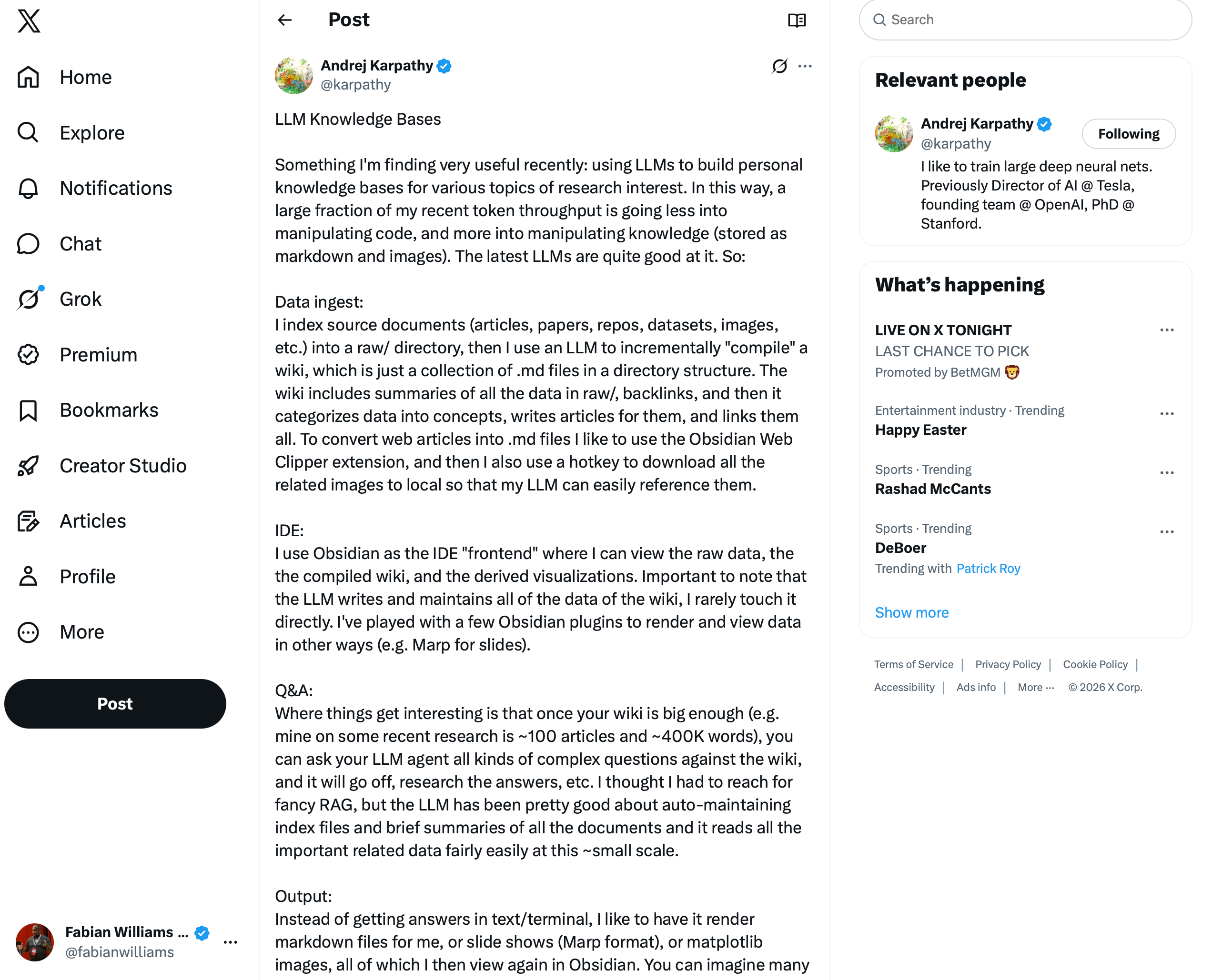
The core idea: stop using LLMs just to write code. Start using them to compile knowledge. Collect raw sources — articles, papers, transcripts, tweets — into a folder. Then have the LLM incrementally build a wiki from those sources. Summaries, backlinks, concept articles, cross-references. All in markdown. All viewable in Obsidian.
I read it and thought: I am already 80% there. I have the Obsidian vault. I have Claude Code. I have transcripts from podcasts I have been watching all week. What I do not have is the pipeline — the thing that turns raw sources into structured knowledge automatically.
So I built it.
What I Had Before
I have been running an Obsidian vault as my second brain since early February 2026. Three work contexts — personal, my side business Adotob, and my day job at Microsoft. A constitutional framework called Ralph v2 for autonomous development. An AI agent named Ada running on a Mac Mini in my house with 40+ cron jobs. Another agent named Mimi running a nonprofit’s operations on a Windows box.
The vault had grown to 2,327 markdown files and 2.3 gigabytes. It was powerful but messy. Research summaries lived next to cron job configs. Podcast notes sat in the same directory as deploy scripts. I had knowledge, but it was not compounding. Every new session started from scratch because nothing was cross-linked.
What Karpathy Got Right
His insight is deceptively simple: the LLM should maintain the wiki, not you. You rarely touch it directly. Your job is to feed it raw sources. The LLM’s job is to:
- Compile raw sources into structured articles
- Cross-link related concepts with backlinks
- Index everything so you can find it
- Lint the wiki for inconsistencies and gaps
- Answer questions against the accumulated knowledge
This is not RAG. At ~100 articles and ~400K words, Karpathy found the LLM handles it fine with auto-maintained index files. No vector database. No embedding pipeline. Just markdown files and a good index.
What I Built
I created four Claude Code skills that implement Karpathy’s pipeline:
/ingest-transcript — Feed a YouTube URL, get a transcript saved to knowledge/raw/transcripts/ with full YAML frontmatter (title, speaker, date, tags, compiled: false). One command. Source is registered automatically.
/wiki-compile — The core skill. Scans knowledge/raw/ for uncompiled sources. For each one, it extracts concepts, people, and tools mentioned. Creates or updates wiki articles in knowledge/wiki/ with summaries, key points, and [[backlinks]]. Updates the master index. Marks raw files as compiled. Idempotent — run it twice, nothing changes.
/wiki-lint — Health checks the wiki for broken links, missing frontmatter, stale articles, orphan pages, and duplicate concepts. Writes a report. Tells me what to fix.
wiki_search.py — FTS5 full-text search over all wiki content. SQLite-based, zero dependencies. Searchable from the command line or by Claude during a session.
The whole thing runs on the filesystem. No database except SQLite for search. No API calls. No cloud dependency. Obsidian is just the viewer.
The First Real Test
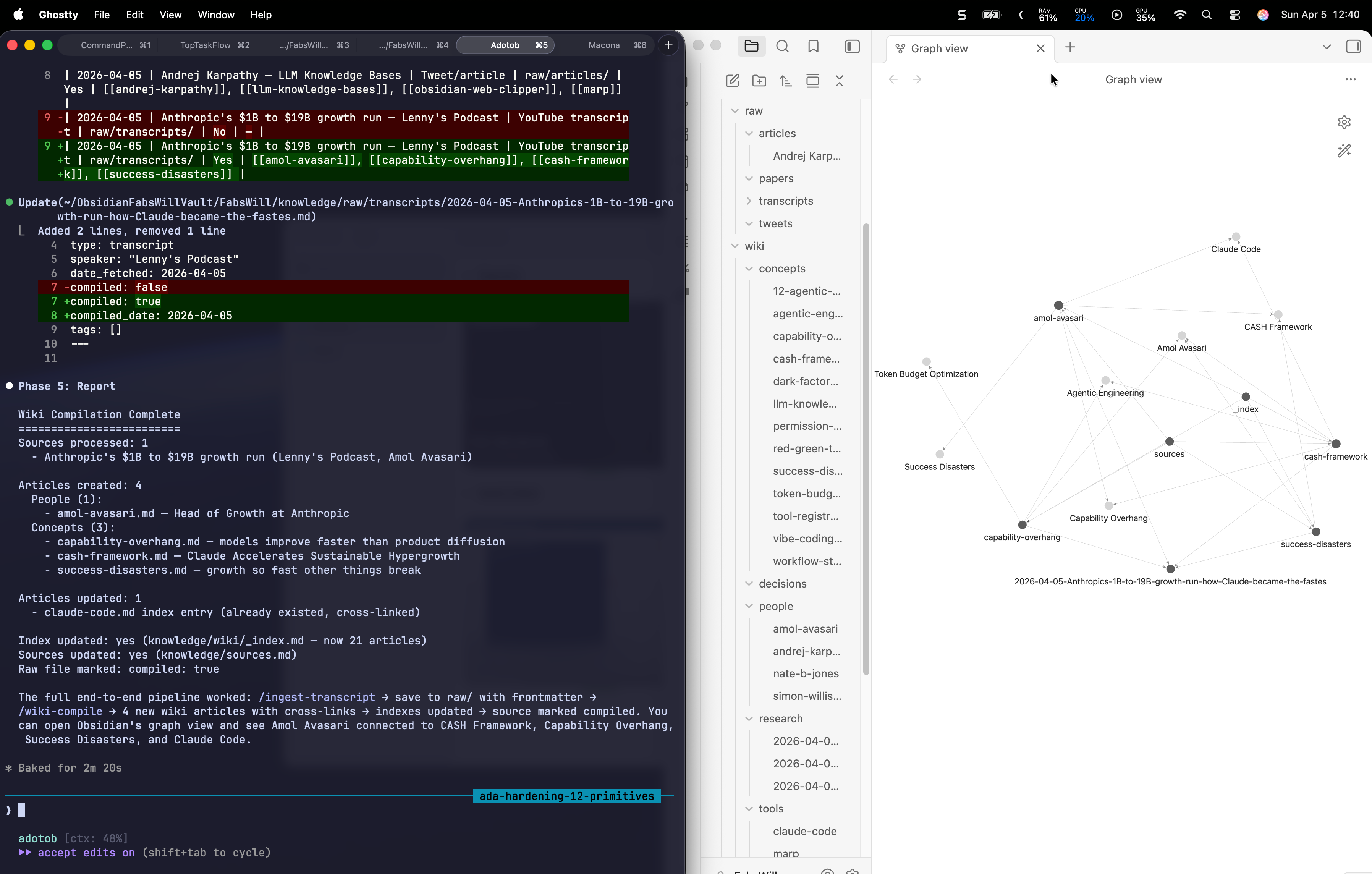
I was watching Lenny’s Podcast interview with Amol Avasari — the head of growth at Anthropic. A third of the way in, I knew I wanted this in my knowledge base. So I ran:
/ingest-transcript https://www.youtube.com/watch?v=k-H4nsOTuxU
Transcript saved. 3,237 segments. Then:
/wiki-compile
Four new wiki articles appeared:
- Amol Avasari — the person, his background, how he cold-emailed his way into Anthropic
- Capability Overhang — models improve faster than products can diffuse the benefits
- CASH Framework — Claude Accelerates Sustainable Hypergrowth, Anthropic’s internal automated growth experimentation
- Success Disasters — when growth goes so fast that other things break
Each article cross-linked to existing articles. Amol connected to Claude Code. CASH Framework connected to Agentic Engineering. Capability Overhang connected to Token Budget Optimization. The knowledge graph grew itself.
The Numbers
After processing five raw sources — three YouTube transcripts, one tweet thread, and one session summary — the wiki contains:
| Category | Count |
|---|---|
| Concept articles | 13 |
| People profiles | 4 |
| Tool evaluations | 4 |
| Total wiki articles | 21 |
| Cross-links between articles | 60+ |
| Raw sources processed | 5 |
| Time to build the pipeline | One afternoon |
| Time to process a new source | Under 2 minutes |
The vault overall: 2,327 markdown files, restructured into a clean hierarchy with knowledge/, projects/, contexts/, ops/, and media/.
What Compounding Looks Like
Here is the thing that Karpathy’s post does not say explicitly but that becomes obvious the moment you use this: every new source makes every previous source more valuable.
When I compiled the Simon Willison transcript two days ago, the article on Agentic Engineering stood alone. When I compiled the Nate B Jones transcript the next day, his 12 Agentic Primitives linked back to Agentic Engineering. When I compiled Amol Avasari today, the CASH Framework linked to both — and the Capability Overhang article gave new context to Token Budget Optimization, which I had written about from a completely different source.
None of these connections were planned. The LLM found them because the wiki structure makes relationships visible. This is the compound interest of knowledge.
Why This Matters Beyond My Situation
I have been writing about autonomous AI agents for months — how to build them, how to trust them, how to keep them honest. This knowledge pipeline is a different kind of agent. It does not send emails or check your bank balance. It builds understanding.
If you are a PM, imagine feeding every user research interview into this pipeline. Within a week you have a cross-linked wiki of user pain points, feature requests, and competitive insights — all searchable, all connected.
If you are an engineer, imagine every architecture decision record, every post-mortem, every RFC living in a wiki that the LLM keeps current. Six months from now, you ask “what did we learn about caching in 2025?” and the wiki has the answer with links to three related decisions.
If you are a founder, imagine every investor conversation, every competitor teardown, every customer call compiled into a knowledge base that compounds. Your pitch deck practically writes itself because the evidence is already organized.
This is what Karpathy means when he says “there is room here for an incredible new product instead of a hacky collection of scripts.” He is right. But you do not have to wait for the product. The scripts work today.
The Practical Setup
If you want to build this yourself, here is what you need:
- Obsidian — free, runs locally, renders markdown beautifully
- Claude Code (or any coding agent) — to build and run the skills
A directory structure:
knowledge/ raw/ ← dump sources here articles/ transcripts/ papers/ wiki/ ← LLM compiles here concepts/ people/ tools/ _index.md output/ ← query results filed backObsidian Web Clipper (browser extension) — one-click save articles to
raw/Patience for the first compile — the LLM needs to read your sources and build the initial wiki. After that, incremental compiles are fast.
The skills I built are Claude Code markdown files. They are not magic. They are instructions the LLM follows: scan for uncompiled files, extract concepts, create articles, update the index. You could adapt the same pattern for any LLM that can read and write files.
Three Lessons
The pipeline is more valuable than any single article. I could have written 21 wiki articles by hand. It would have taken days and I would never maintain them. The pipeline means every YouTube video I watch, every article I read, every tweet that catches my eye becomes part of a growing knowledge base — automatically.
Cross-links are the superpower. Individual notes are useful. Cross-linked notes are transformational. The moment Amol Avasari’s Capability Overhang connected to Nate B Jones’s Token Budget Optimization, I saw a relationship I had not noticed before — the cost problem and the adoption problem are the same problem viewed from different angles.
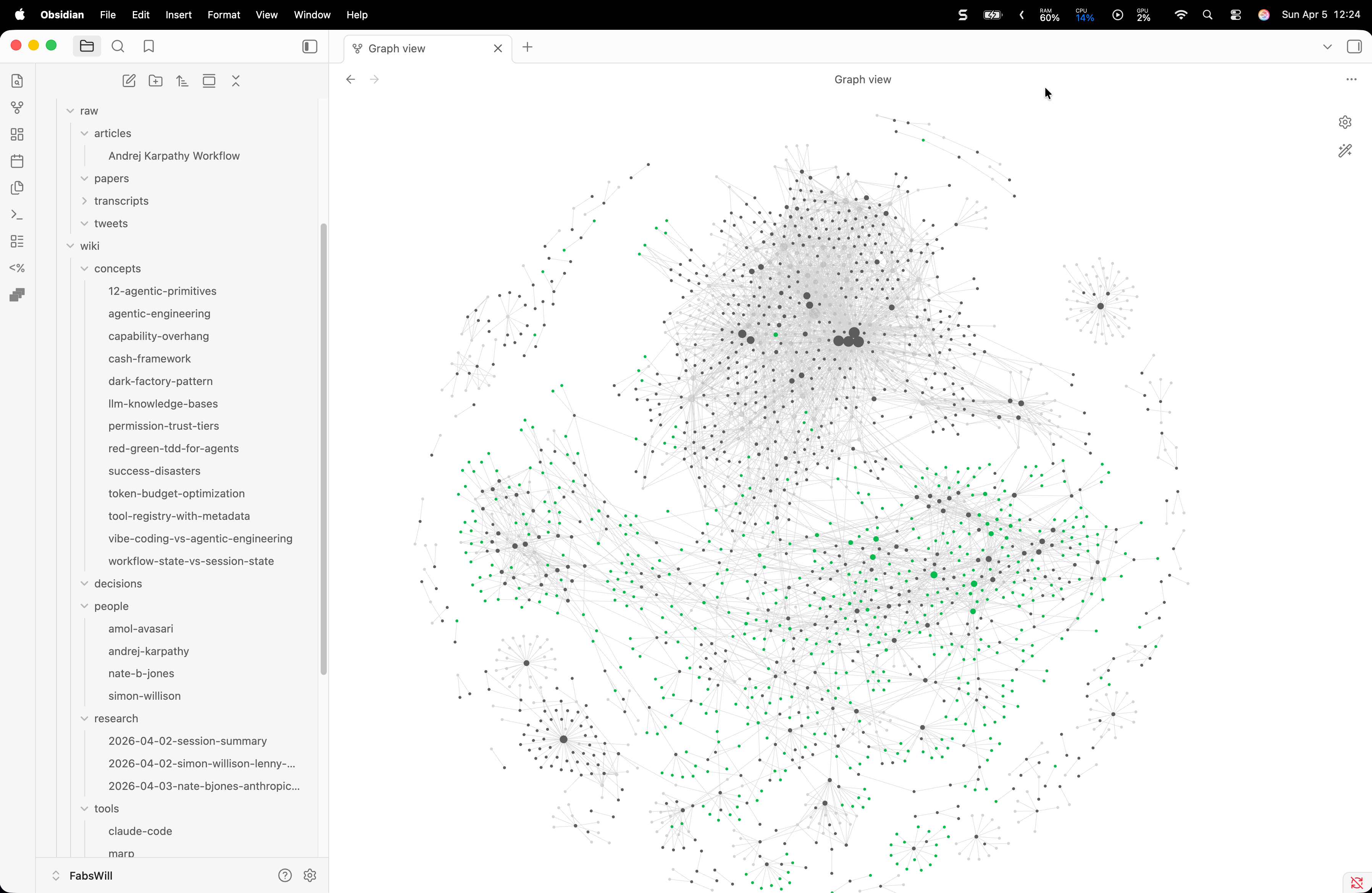
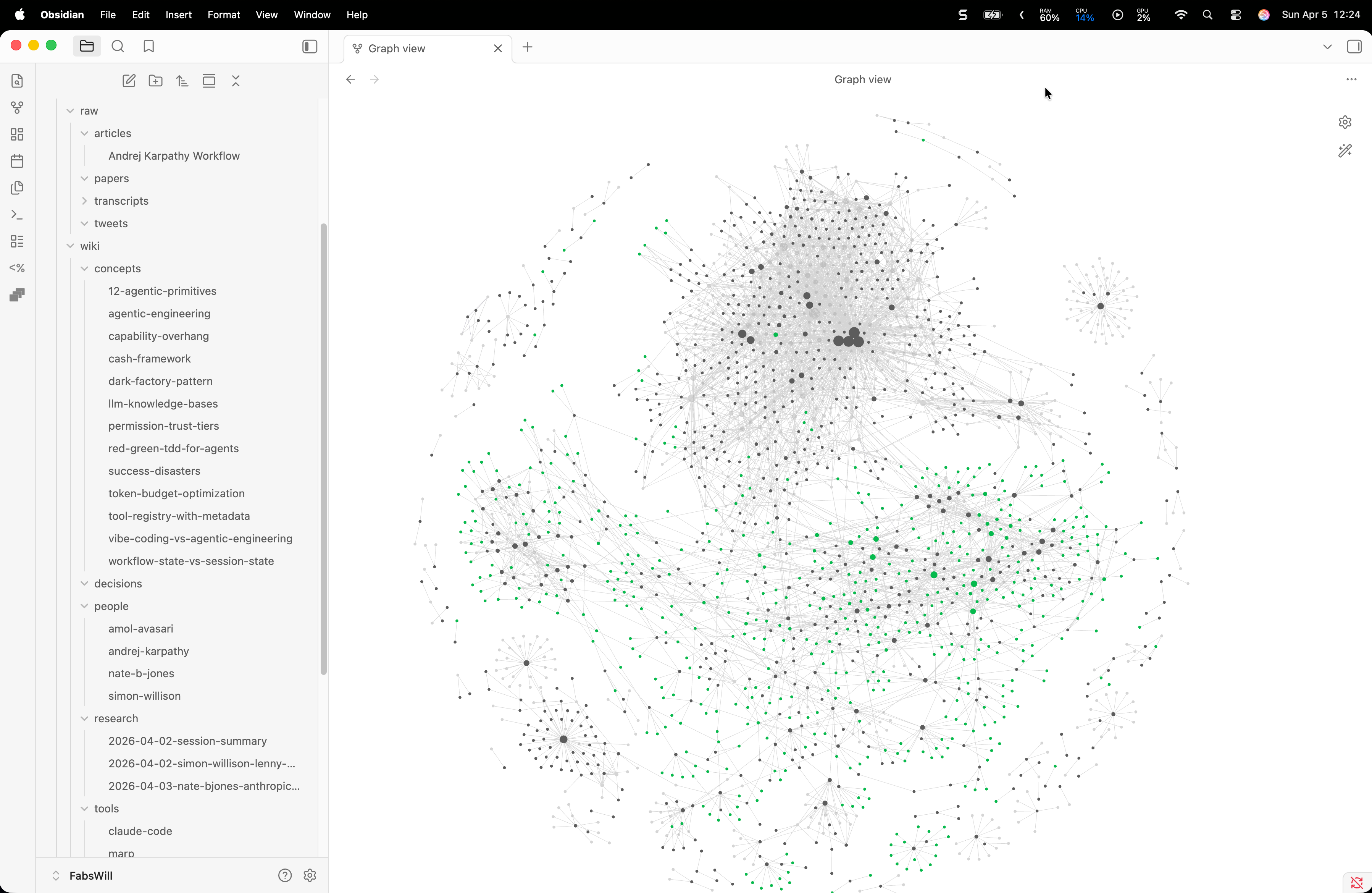
Obsidian’s graph view is the reward. You can see the knowledge growing. Nodes appear, edges form, clusters emerge. It is deeply satisfying in a way that a folder of markdown files is not. The visual feedback makes you want to feed it more sources.
I built this pipeline in one session on a Saturday afternoon. It will run for years. Every podcast I watch, every article I clip, every research thread I follow — it all compounds now.
That is what Karpathy got right. The LLM is not just a tool for answering questions. It is a tool for building the thing that answers questions.
If you are interested in autonomous AI agents, knowledge management, or just building cool things on your Mac, I write about all of it here. I also run Ada — an AI family assistant on a Mac Mini — and Mimi — an AI executive assistant for a nonprofit. Both of them are getting this knowledge pipeline next.
Cheers, Fabian Williams