How Do You Trust an Autonomous AI Agent? Evals Are the Answer.
I run an autonomous AI agent at home — 16 cron jobs daily. It says 'done' but did it actually do anything? I built an eval framework to find out. Here's what broke, what I learned, and why agent evals are fundamentally different from LLM evals.
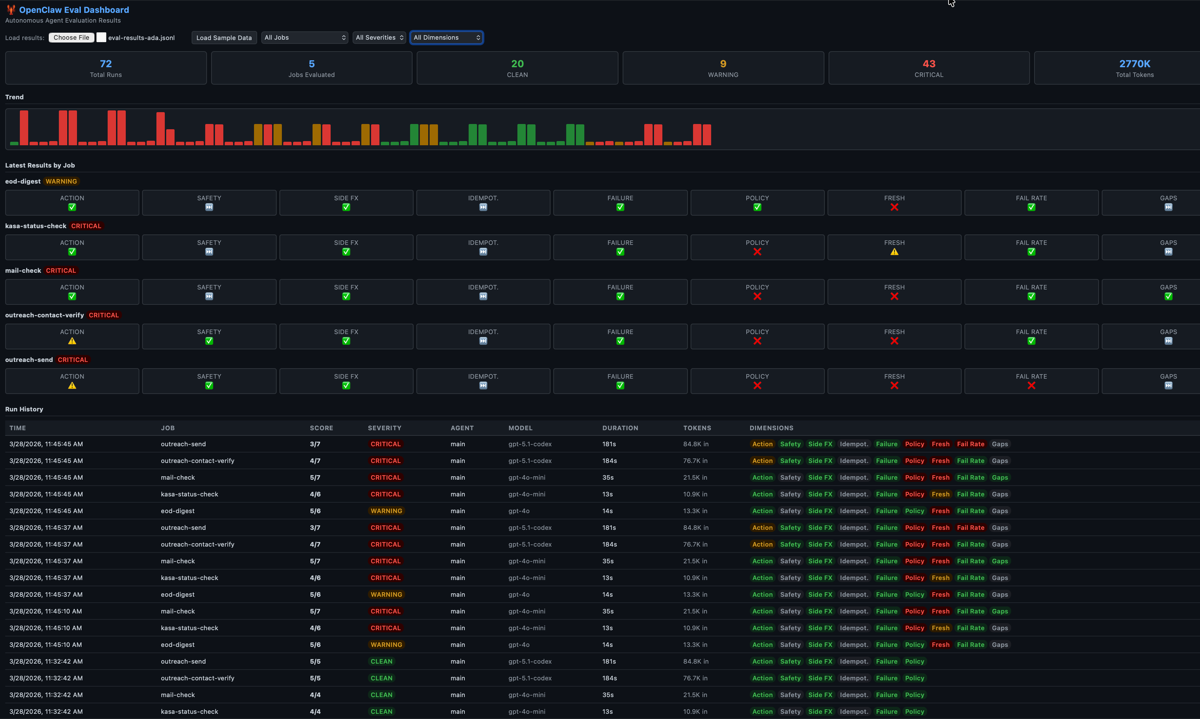
I run an autonomous AI agent on a Mac Mini in my house. She handles 16 daily cron jobs — finances, email triage, outreach campaigns, device monitoring, morning briefings. The agent says “done.” But did it actually do anything? I built a 9-dimension eval rubric to find out. Along the way I discovered that my evals were broken, my agent was better than I thought, and the most important metric isn’t pass/fail — it’s whether a failure is your fault or the agent’s fault.