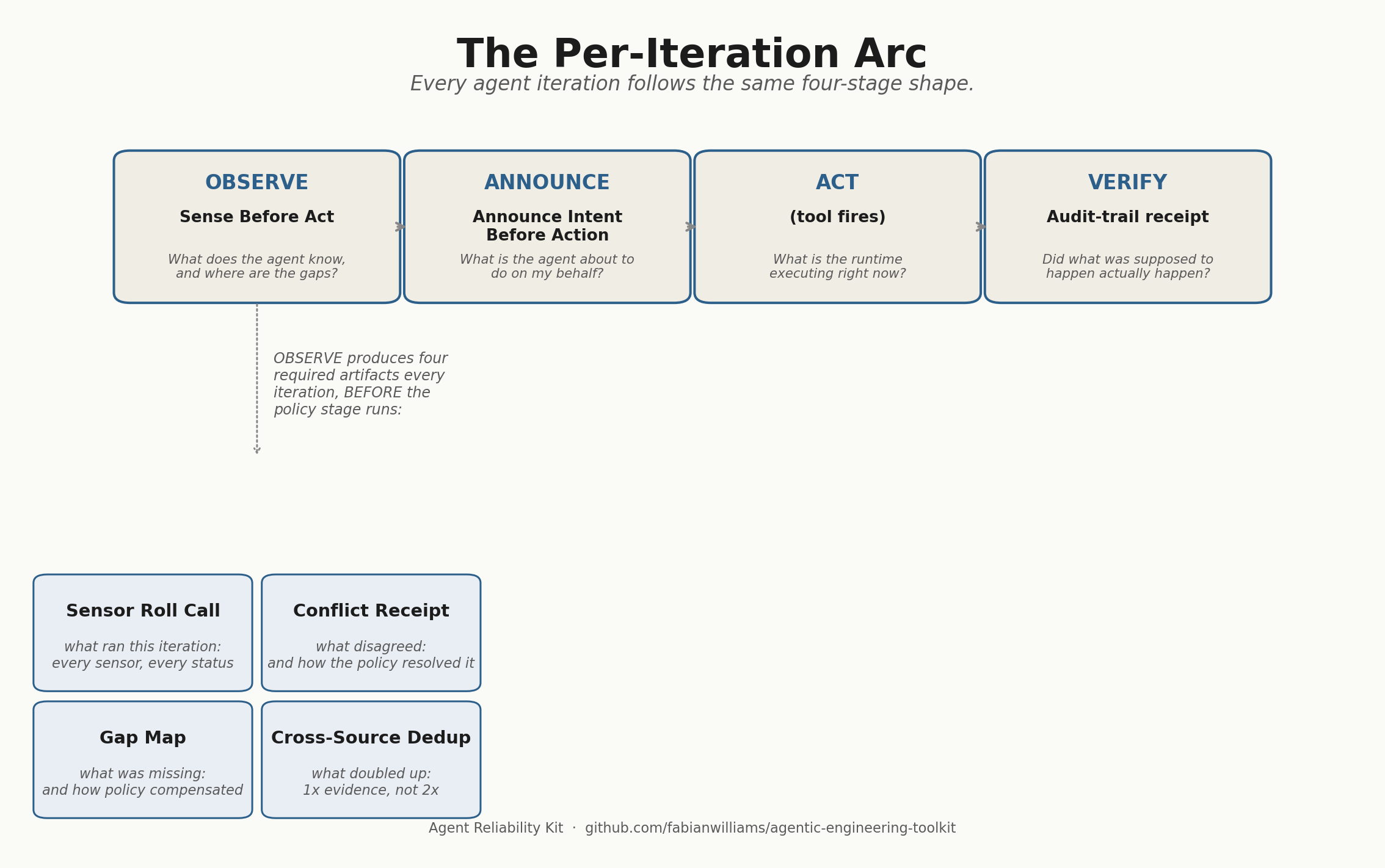
Your Agent Said It Did the Work. I Checked the Disk.
I run a six-agent fleet for a non-profit. One morning the agents began reporting work they never did. Here is the fabrication pattern, and the receipts discipline that fixed it.

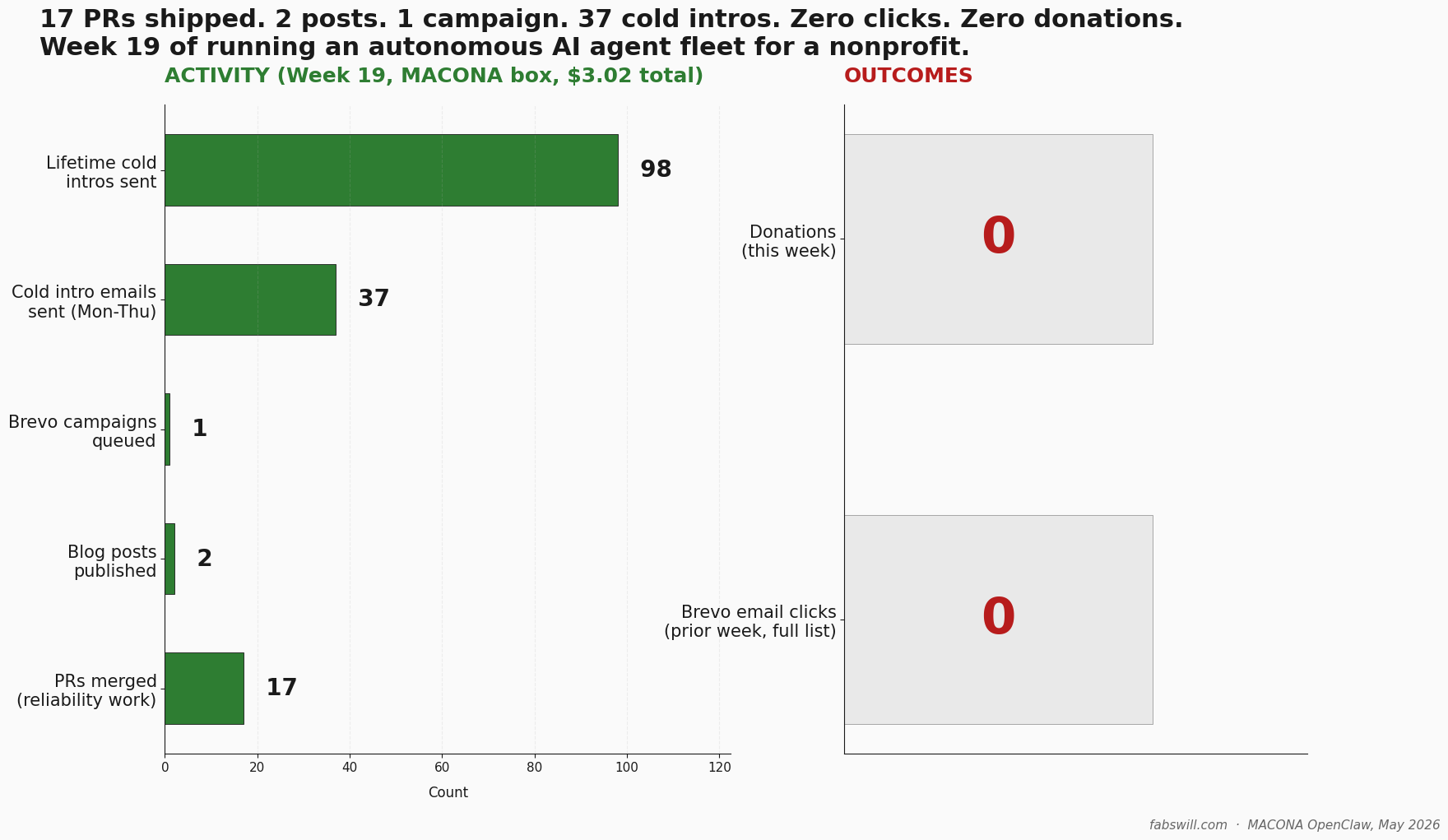
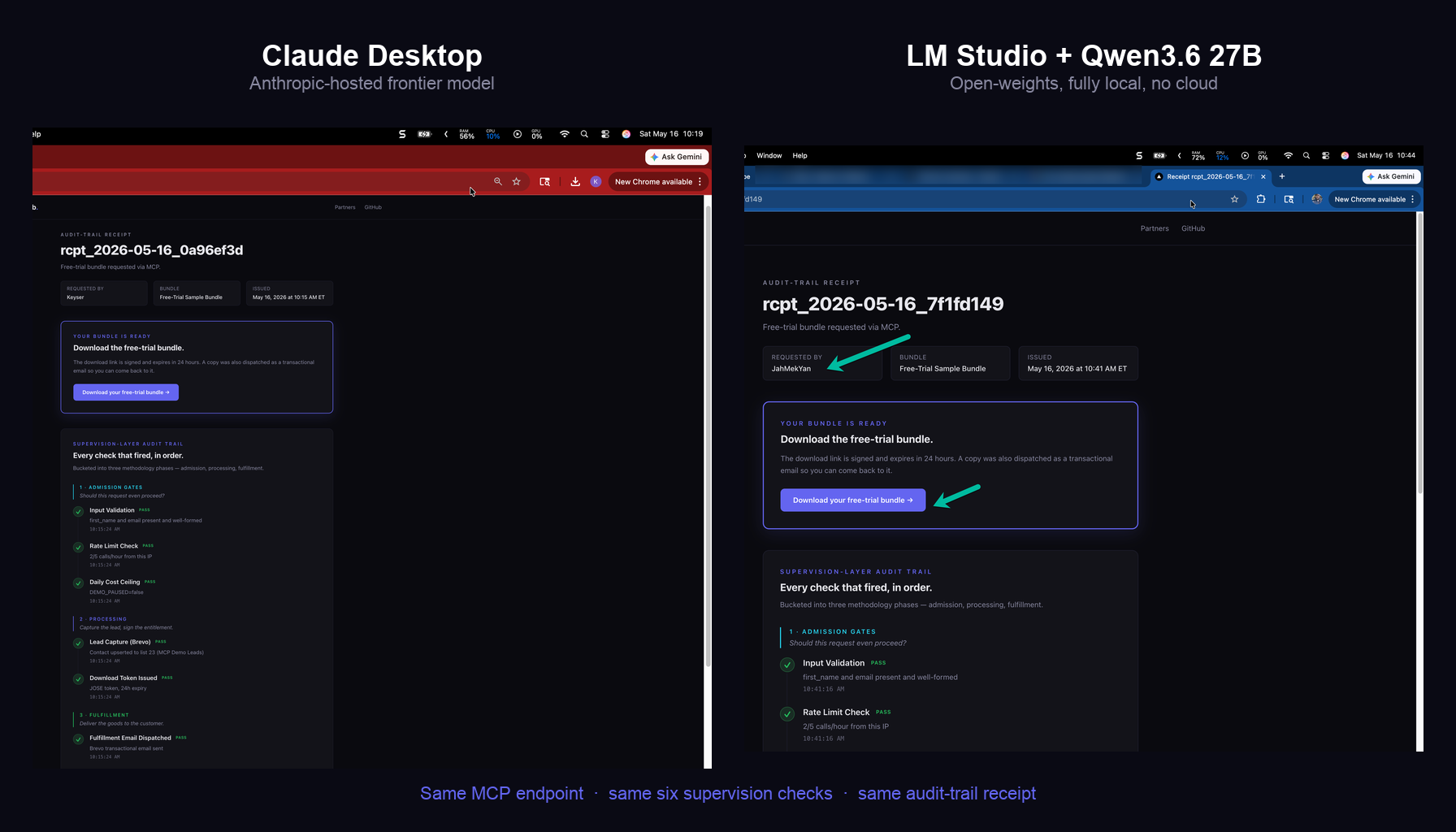
Every morning one of my agents sends me a clean status report. Posts cross-posted. Messages delivered. Contacts processed. For a while I read those reports the way you read a receipt from a cashier you trust. Then the automation started giving me time back, so I sat down to run a retrospective and checked the reports against what was actually on disk. The trust did not survive contact with the evidence.