One Agent Receipt, Two Buyers: Why Protocol-Neutral MCP Audit Trails Matter for Both Security AND Finance
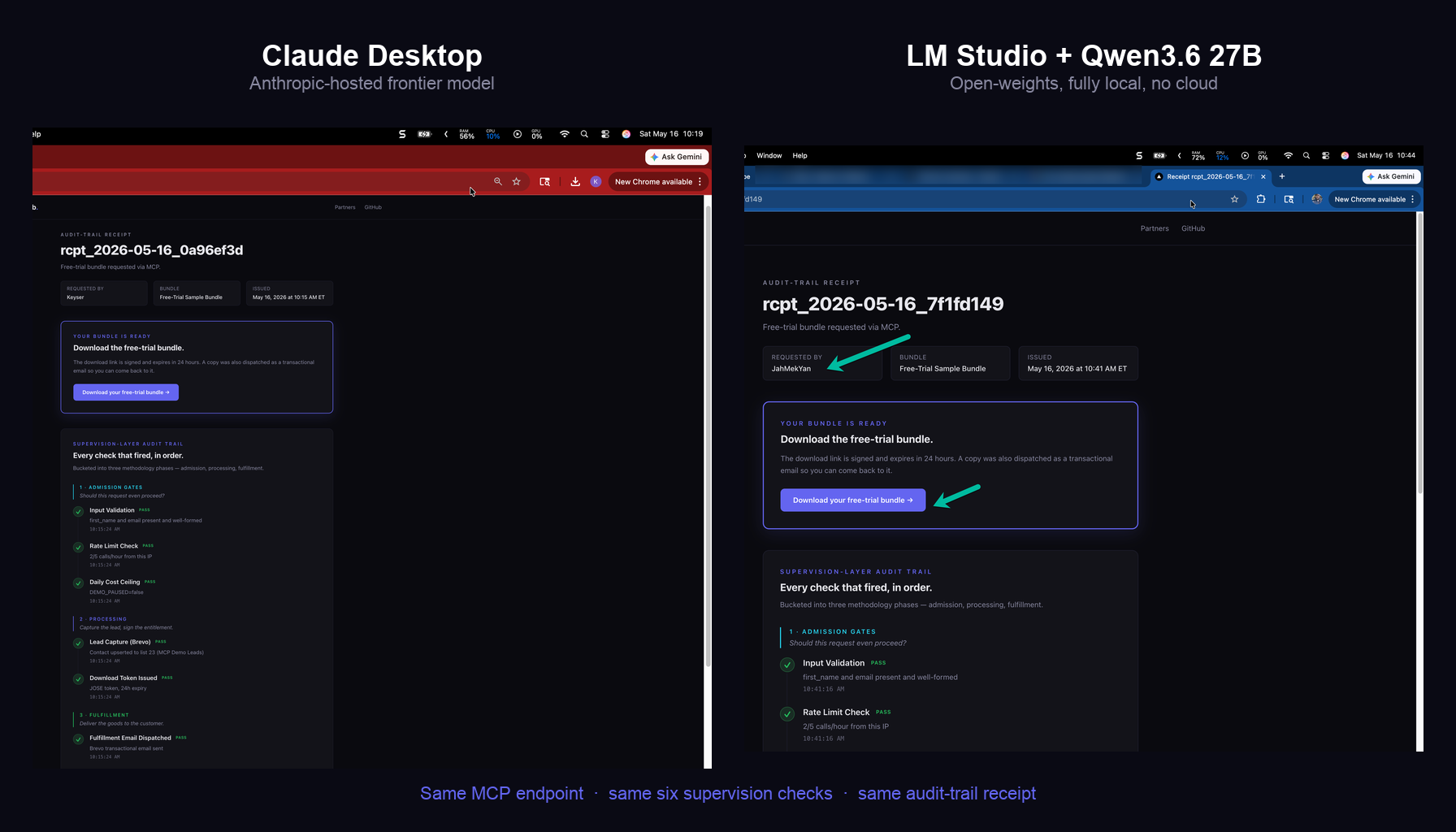
I built a public MCP-callable storefront. The same endpoint produced an identical audit-trail receipt from hosted Claude Desktop AND from Qwen3.6 27B running fully offline on my MacBook. Same six supervision checks. Same receipt page. One artifact that satisfies both the security audit and the finance billing conversation.
Update, 2026-05-19: A2A agent-card now live at mcp.adotob.com/.well-known/agent.json, published 24 hours after Nate B Jones’s IO-2026 video named the agent-card primitive as the second of the four core agent-protocol layers. Three of the four layers of the open-protocol stack are now live in the storefront: MCP for tool access, A2A for agent discovery, and AG-UI manifested as the public receipt page. AP2/X402 is reserved for the MVP-2 paid Stripe flow.
By the end of this post you’ll have two public URLs you can forward to your security team AND your finance team — and both audits get satisfied by the same document. That document is an agent receipt. The two URLs are real receipts produced by the same MCP endpoint, one driven by Anthropic-hosted Claude Desktop and the other driven by Qwen3.6 27B running fully offline on my MacBook. The point of this post is why that one-artifact-two-ledgers property matters more than the technology that produces it.
The two receipts
Let me get the demonstration out of the way before the argument.
Same endpoint: https://mcp.adotob.com/api/a2a/mcp.
Same six supervision-layer checks, bucketed into three methodology phases. Same audit-trail receipt format, served from the same Azure Blob, signed by the same JOSE HS256 download token, with the same Brevo-mediated fulfillment email landing in the same Gmail inbox.
Different clients calling the tool.
- Receipt 1 — driven by Claude Desktop (Anthropic-hosted frontier model, requires their cloud): rcpt_2026-05-16_0a96ef3d
- Receipt 2 — driven by Qwen3.6 27B (open-weights, running fully offline in LM Studio on a MacBook Pro M3 Max, no cloud inference whatsoever): rcpt_2026-05-16_7f1fd149
Click both. They render identically. The receipt page does not know — and does not care — which client called the tool. That property is the whole essay.
If you want to reproduce this on your own machine in two minutes, the operator-verified walkthrough with all 16 screenshots is here: Happy-Path SOP.
What MCP actually solves (and what it doesn’t)
A brief fence so we are not talking past each other.
MCP — Model Context Protocol — is a JSON-RPC 2.0 wire format that lets any LLM-using client discover and call tools from any server. The good version of this story is “one tool definition, many clients.” The hyped version of this story is “AI app stores.” Both miss the part that actually matters for partner-facing commerce.
What MCP gives you that REST APIs did not:
- Discovery. A client points at a URL, calls
initializeandtools/list, and learns what tools exist. No manual tool definition copied into the SDK. No vendor docs to read. - Permission gating built into the client. Most MCP clients ask the user before invoking a tool the first time. The trust boundary is explicit and visible.
- Provider neutrality at the protocol level. The same endpoint serves Claude, ChatGPT (custom connectors), LM Studio, Cursor, Windsurf, Cline, Continue, Zed, and any code calling the MCP SDK or the OpenAI Responses API. Nobody owns the protocol.
What MCP does not give you:
- An observability story for your customers.
- A receipt your partners can forward to their security team.
- A chain of custody for billable agent actions.
That gap is what I have been building toward.
The dual-ledger framing — one artifact, two buyer concerns
Here is the thing I want to make sticky.
A receipt produced by an agent transaction has to satisfy two completely different procurement conversations, often in the same building, often at the same client.
Conversation A — security / audit ledger. The CISO and the procurement reviewer want to know: show me your evals — how do you know the agent did the right thing? They want evidence that input was validated, that abuse limits were enforced, that the system refused to run when its own cost gate said stop. They are looking at the receipt as proof of supervisor behavior.
Conversation B — finance / billing ledger. The CIO, the CFO, the agent-economy product owner want to know: when an agent transacts on a user’s behalf, what is the proof of what it did and when, so we can bill, reconcile, dispute, refund? They are looking at the receipt as chain of custody for billable actions. Salesforce Agentforce charges per conversation. Microsoft 365 Copilot has per-message metering. SAP Joule charges per autonomous action. The moment your agent stack moves to per-action billing, every action needs a receipt or finance refuses to sign the renewal.
These are the same question dressed in different ledgers. Same forensic property: what happened, in what order, with what inputs, against what guardrails.
The receipt I built answers both with one URL.
That is not a small thing. It collapses two procurement reviews into one document. It eliminates the “can your vendor logs be exported in CSV for our billing reconciliation?” call. It means the partner you license your methodology to can hand the same URL to the CISO and the CFO and watch both sign-offs happen in parallel.
The closest existing pattern is the credit-card receipt: one document, recognized by the cardholder, the merchant, the issuing bank, the acquiring bank, the dispute system, the tax authority. Different actors, different ledgers, same primary artifact. Agent commerce needs the same shape.
What is actually on the receipt
The methodology behind the receipt is a three-phase supervision lifecycle. Here is the same lifecycle the partners page draws, because it is the same discipline running underneath the receipt page:
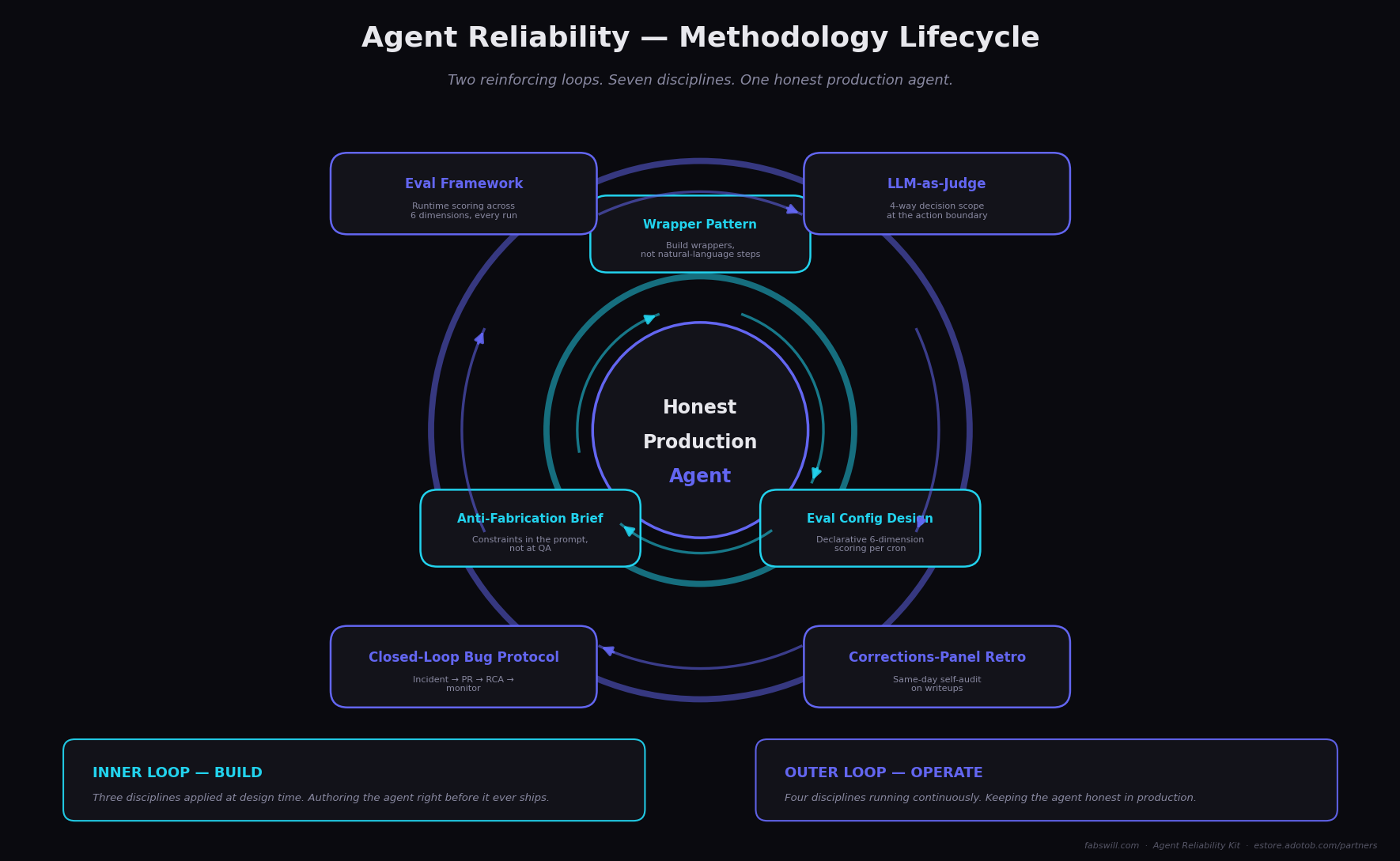
The supervision lifecycle behind every check on the receipt — admission, processing, fulfillment. Same shape on the partners page slide, same shape in production.
Three methodology phases. Six checks. Every check has a timestamp, a pass/fail/skip/warn badge, and a one-line explanation.
Phase 1 — Admission gates. Should this request even proceed?
- Input validation — first_name and email present and well-formed
- Rate limit — under 5 calls/hour from this IP (cap protects the demo from abuse)
- Daily cost ceiling — server confirms it has not exceeded its $5/day cap
Phase 2 — Processing. Capture the lead, sign the entitlement.
- Lead capture (Brevo) — contact upserted to the dedicated MCP-leads list
- Download token mint — JOSE HS256 JWT issued with 24-hour expiry, signed with the eStore’s secret so the eStore can validate it cross-app
Phase 3 — Fulfillment. Deliver the goods to the customer.
- Fulfillment email dispatched — Brevo transactional API confirmed message acceptance
Here is what that looks like rendered for a real run — the publicly readable receipt page from the Claude Desktop example at the top of this post:
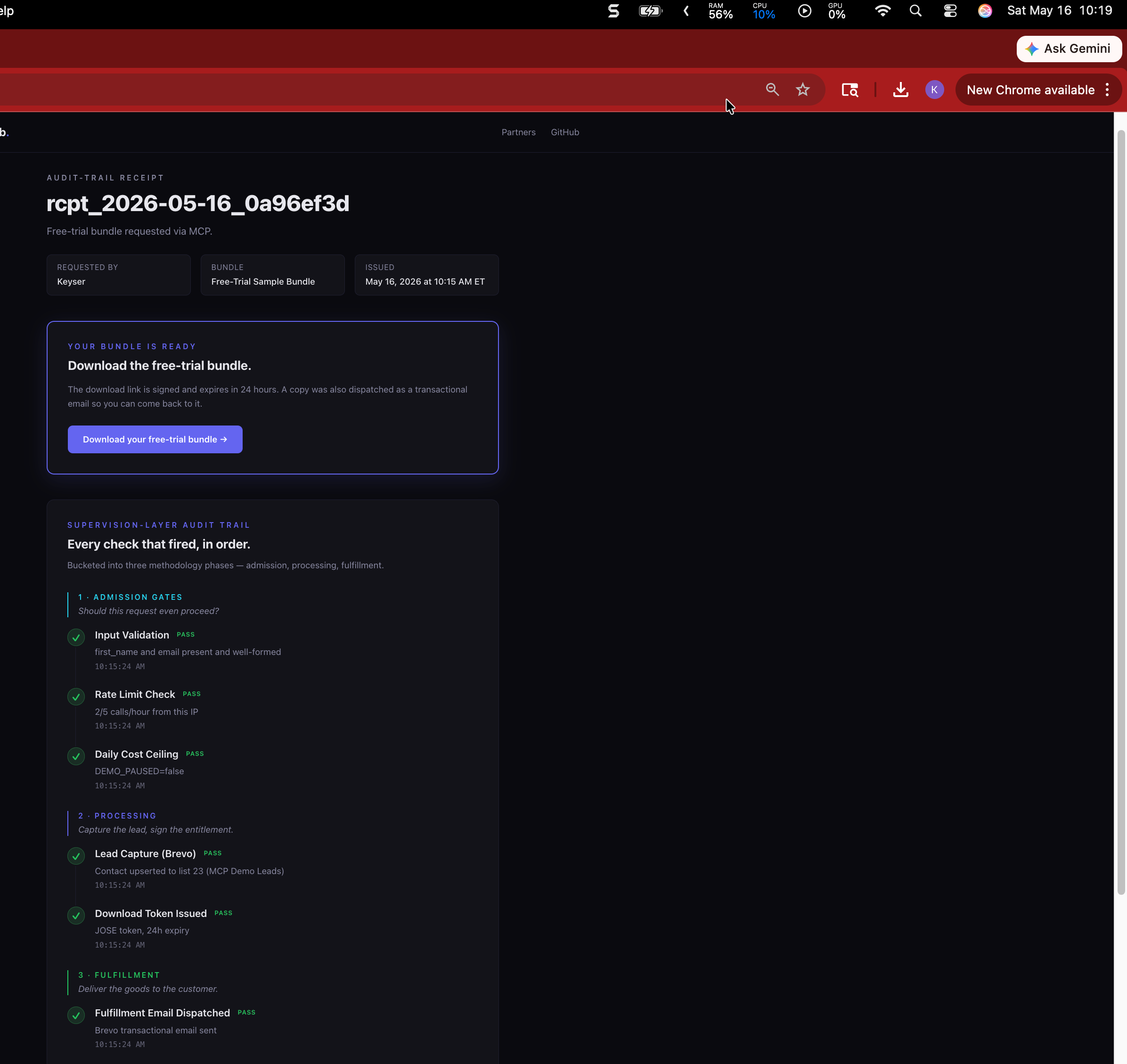
Every check has a timestamp, a status badge, and a one-line explanation. The page is publicly readable; no login, no privileged role, no vendor-dashboard access. The requester’s email never appears on this page — only the first name.
That is the entire system. Six checks. The receipt page renders the list with the same visual discipline whether all six passed, three failed, or the request was admission-rejected at step one. The audit trail is honest — including about its own failures. A failure receipt that does not pretend everything worked is more valuable for a partner conversation than a no-receipt-on-failure system that hides degraded behavior.
This is the discipline I have been calling the Agent Reliability Kit™. The MCP storefront is the public, end-user-facing instance of those patterns running in production. The receipt is what the patterns look like from the outside.
The protocol-neutrality surprise
Here is the move that opens the partner objection.
The dominant question when I show partners this demo is: “does this work in our stack? We are not a Claude shop.”
The two receipts at the top of this post are the answer. One was driven by Claude Desktop (an Anthropic-hosted frontier model). The other was driven by Qwen3.6 27B — a 27-billion-parameter open-weights model, downloaded once, loaded into LM Studio, running entirely on a MacBook Pro M3 Max with no inference request ever leaving the laptop except the single MCP tools/call to mcp.adotob.com.
Same endpoint. Same six checks. Same receipt URL format. Same fulfillment email arrived in the same inbox.
What this means in practice for any team evaluating the methodology for licensing:
- Your existing agent stack — OpenAI, Azure OpenAI, Bedrock, Vertex AI, on-prem open weights, some mixture — is already compatible. No rebuild. No vendor migration.
- Your client’s security review is a URL forward, not a 40-slide deck.
- The audit trail is observable from the consumer side without privileged access. Every partner, every client, every regulator, every auditor — same view.
If you have ever sat in a procurement call where the vendor says “we have full audit logs” and the buyer says “great, can our team see them?” and the vendor says “we would need to set up a dashboard role, give us two weeks” — you know exactly why consumer-readable receipts matter.
What this means if you are building agent-to-agent commerce
A handful of things, ranked by how often they come up in partner conversations.
You stop selling “trust me.” The audit trail is a URL. Partners can hand it to their client’s security team without you. They can hand it to their CFO without you. The conversation moves from “explain your evals” to “click this and see for yourself.”
You stop picking a vendor for your customer. Most agent platforms ship as a vertically integrated stack — pick our model, pick our orchestrator, pick our observability tool, accept our SLA. MCP-callable patterns invert that. The customer picks the model, the customer picks the client, you pick the receipt discipline. You sell methodology, not framework.
You handle failure visibly. Receipt-on-success is easy. Receipt-on-partial-failure is the discipline. Every check on the receipt page renders with its real status. A skipped lead-capture step renders as SKIP, not as silence. A failed input validation renders as FAIL and the downstream five checks render as SKIP with timestamps. Auditors trust audit trails that admit limitations. They distrust ones that always look clean.
Per-action billing becomes legible. If you are going to charge per agent action, the buyer needs the action ledger to be unambiguous. The receipt format above is one way to make it unambiguous. There are others. Pick one.
Try it, then license it
Two URLs already linked above. Two minutes from Settings → Connectors → Add MCP server to a real receipt in your inbox. The walkthrough with screenshots is operator-verified and lives at the same repo: Happy-Path SOP.
If you build agents for clients and you want the non-sanitized examples, the white-label rights, and the partner relationship behind this methodology, that is what the licensed Agent Reliability Kit is for: estore.adotob.com/partners. The free OSS reference implementation is here: github.com/fabianwilliams/adotob-mcp (Apache 2.0). The broader public Kit is at github.com/fabianwilliams/agentic-engineering-toolkit.
What this piece contributed
Three things I want you to walk away with:
- A live, public, MCP-callable storefront you can hit from any MCP-capable client right now and receive an audit-trail receipt URL. Not a slide. Not a demo video. A URL.
- A dual-ledger framing for agent receipts — same artifact, satisfies the audit conversation AND the billing conversation. Sell once, two procurement signatures, no second integration.
- Two worked examples — Anthropic-hosted Claude and fully-local Qwen3.6 27B — producing receipts that are byte-for-byte structurally identical. Protocol-neutrality is no longer a slide claim; it is a pair of URLs anyone can click.
If you are a builder shipping agents into client work, this is the methodology you can either rebuild yourself from the OSS reference or license the long-form version of. Either path works. The one path that does not work anymore is shipping agent commerce without a receipt your customer can read without your help.
Cheers, Fabian Williams
I build autonomous AI agents and the operational infrastructure to keep them honest — for nonprofits, small businesses, and enterprise teams. If you are evaluating agent-receipt patterns, MCP-callable storefronts, or partner-facing audit trails for licensing into your own consulting practice, I would like to hear what you are working on.
- Blog: fabswill.com
- LinkedIn: fabiangwilliams
- Twitter/X: @fabianwilliams
- MCP storefront: mcp.adotob.com
- Agent Reliability Kit (OSS): agentic-engineering-toolkit
- Partner licensing: estore.adotob.com/partners
Agent Reliability Kit™ is a trademark of Adotob Solutions.