Paying Down Supervision Debt: Why the Five Control Points That Decide Whether Your Agent Ships Have Nothing to Do With Your Model
Five infrastructure control points decide whether an agent reaches production. The Agent Reliability Kit sits on one of them: observability. A public, consumer-readable audit-trail receipt that satisfies both the security review and the finance review with the same URL.

By the end of this post you will know which of the five infrastructure control points your agent stack is shipping without, and you will have a concrete pattern for paying down the observability piece of that debt: a public, consumer-readable audit-trail receipt that satisfies both your security team and your finance team with the same document. The receipt was already in production when the broader practitioner conversation started naming the gap.
The thing most agent-shipping teams have not noticed yet
The companies that decide whether your agent reaches production are not the model labs. They are five infrastructure layers that almost nobody has on a roadmap: Runtime. Identity. Data. Tool / write access. Observability. Plus a multilayer kill switch sitting across all of them.
The framing is sharp because it is correct. Compute is necessary but not sufficient. The next bottleneck after “we have enough GPUs” is “can we govern what the agents actually do.” Most teams ship one layer of governance and call it human-in-the-loop. That is not human-in-the-loop; that is a prompt.
The cumulative gap between the supervision an agent system claims to ship with and the supervision it actually ships with has a name in 2026 product circles: supervision debt. It is the trust deficit your stack accumulates when it ships features faster than it ships controls. Eventually a procurement reviewer asks for the controls and you have to either produce them or refund the engagement.
This post is about paying down one specific slice of supervision debt: the observability control point. The slice that determines whether a CISO asking “show me your evals” gets a slide deck or a URL.
The five control points, in one table
| Layer | What it answers | Operators in 2026 |
|---|---|---|
| Runtime | Where does the agent live and run? | Cloudflare Agents SDK, AWS Bedrock AgentCore, Vercel AI Gateway |
| Identity | Who is the agent acting for? | Auth0 / Okta for AI Agents, WorkOS, Microsoft Entra Agent ID, AWS AgentCore Identity |
| Data | What can the agent know? | Snowflake Cortex Agents, Databricks, governed semantic layers |
| Tool / write access | What can the agent change, with what blast radius? | (cross-cutting; lives in tool registries and MCP tool descriptions) |
| Observability | What did the agent actually do? | Datadog LLM, Arize, custom audit-trail patterns |
Plus the kill switch, which lives across all five plus payment: runtime cancel + identity revoke + gateway block + payment freeze + workflow interrupt.
If you can confidently fill in your operator name on every row, you do not have supervision debt. If three of the rows are blank or the answer is “we have logs in Datadog,” you have supervision debt and a partial answer for one row. The rest of this post is about paying down the last row honestly.
“Show me your evals” is not a question about your evals. It is a question about your observability control point, asked in security-team vocabulary.
Why “show me your evals” is the wrong question to optimize for
The default response most agent vendors give when their client’s CISO asks for evals is: “we run automated test suites in CI, we monitor LLM outputs in production, and we have an internal eval dashboard you can review under NDA.”
Every part of that response is a confession of supervision debt.
- “Automated test suites in CI”: testing covers the deterministic substrate. It does not cover agent runtime behavior, where the model is the variable.
- “We monitor LLM outputs”: monitoring is the wrong primitive. Monitoring is what you do when you have a dashboard and a hope. Verification is what you do when you have a contract and proof.
- “Internal eval dashboard, NDA review”: the buyer has to take your word and your sales engineer’s time. Every renewal requires the same dance. The supervision-debt interest payment is the procurement cycle.
What the CISO actually wants is a URL their team can fetch without a privileged account. What the CFO wants, at the same client, is a record of every billable action the agent took on their behalf. What the CIO wants is proof that the supervision discipline you sold them is actually firing in production.
All three are the same artifact. We have been calling it an audit-trail receipt. The broader practitioner conversation has been calling it the observability control point. Same primitive in different vocabularies.
How the receipt pays down the observability debt
Two weeks ago we shipped a public MCP-callable storefront at mcp.adotob.com. Any MCP-capable client can call the purchase_free_bundle tool. Each call produces a publicly readable receipt URL like:
https://mcp.adotob.com/a2a/receipt/rcpt_2026-05-16_0a96ef3d
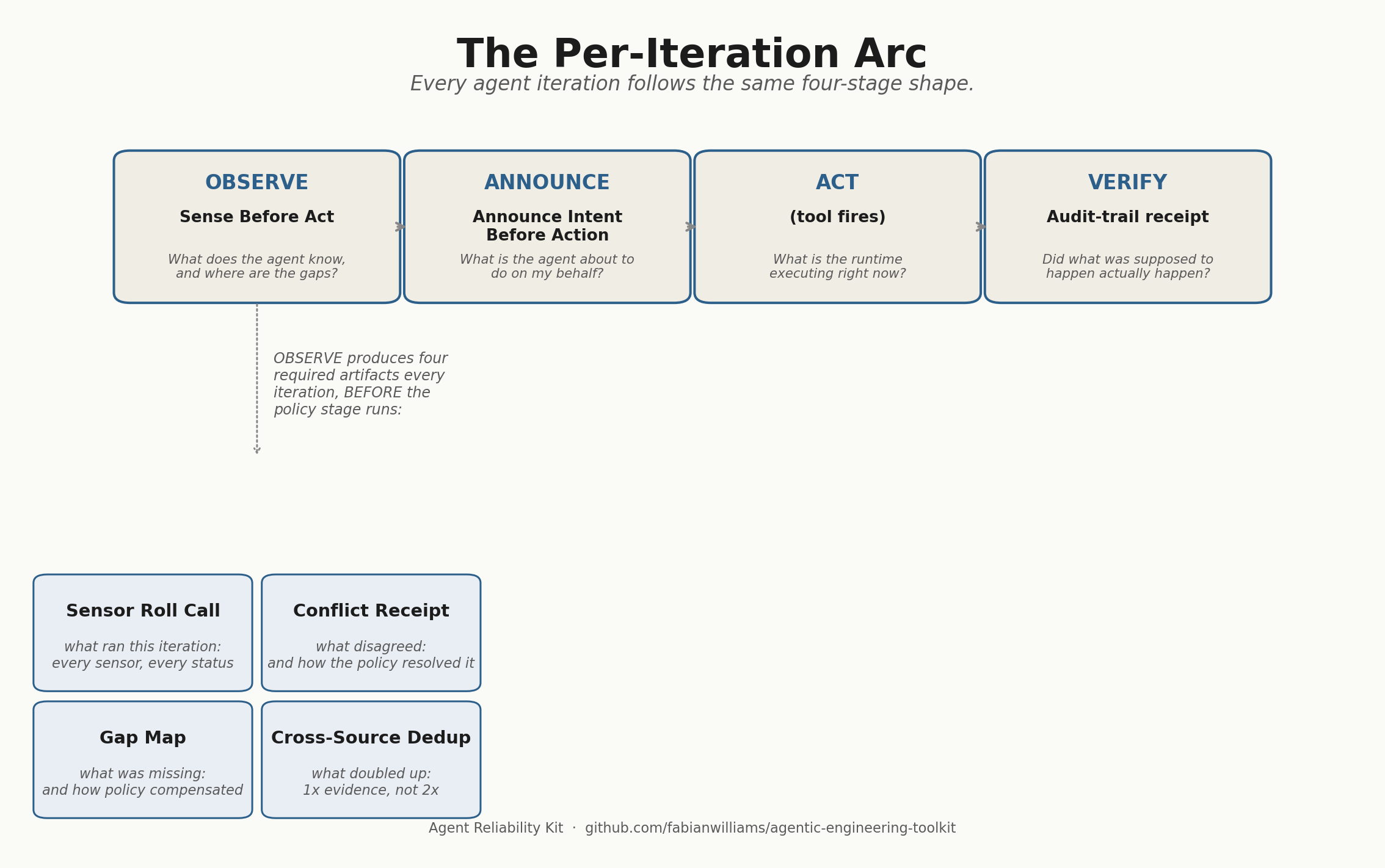
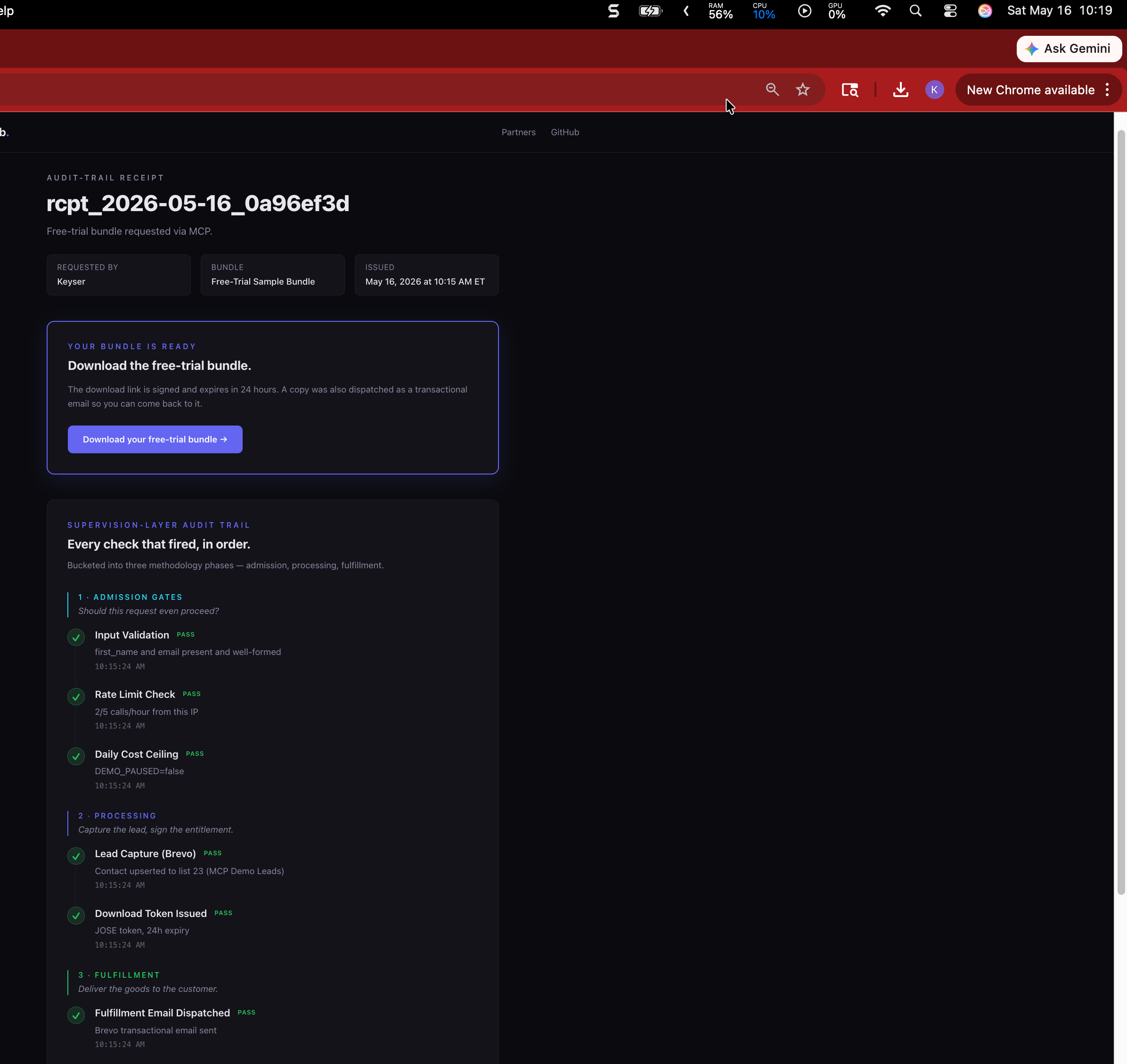
The receipt enumerates six supervision checks bucketed into three methodology phases:
- Admission gates: input validation, rate limit, daily cost ceiling
- Processing: lead capture (CRM upsert), download token mint (24-hour expiry)
- Fulfillment: transactional email dispatched
Every check renders with a timestamp and a pass / fail / skip / warn status. The page is public; no login, no NDA, no dashboard role. The buyer’s security team and finance team see the same document.
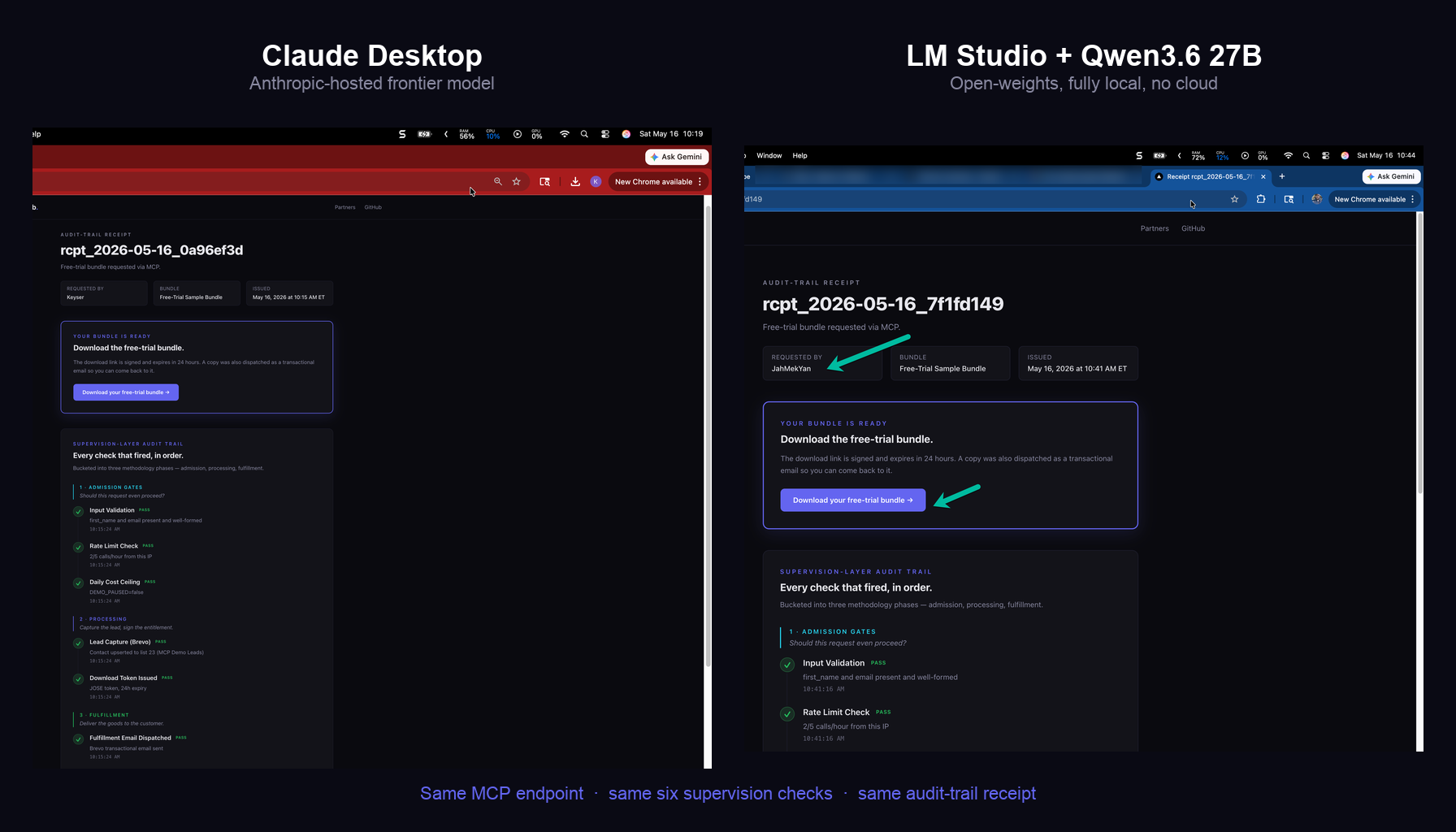
 A real receipt rendered from the live MCP storefront. Six checks, three phases, one publicly readable URL. The page renders identically whether the call came from hosted Claude, a fully-local Qwen3.6 27B, or any other MCP-capable client.
A real receipt rendered from the live MCP storefront. Six checks, three phases, one publicly readable URL. The page renders identically whether the call came from hosted Claude, a fully-local Qwen3.6 27B, or any other MCP-capable client.
Where this pays down supervision debt:
- The buyer no longer has to take the vendor’s word for what supervision fired. The check log is the artifact. Disagreements about whether a control was applied get settled by a URL, not a sales call.
- Failure paths produce receipts too. A failed input validation renders as
FAILand the downstream five checks render asSKIPwith timestamps. Auditors trust audit trails that admit limitations. They distrust audit trails that always look clean. - The same artifact serves two buyers. The CFO reads the same URL as the CISO. The shared source of truth eliminates the reconciliation problem most enterprise agent platforms solve by handing each function a different dashboard.
The receipt is the observability control point in deliverable form. It does not replace Datadog or Arize; it sits in front of them as the buyer-facing surface that survives a forwarded link without leaking PII or requiring privileged access.
How the announce-intent-before-action discipline pays down the debt earlier
Receipts pay down the observability debt after an action fires. The matched-pair discipline pays it down before: the tool description must enumerate every server-side effect the call will produce, in seven categories.
- Data side-effects: what does the server store, where, for how long
- Identity side-effects: create, update, or delete a contact / account
- Communication side-effects: email, SMS, push notification
- Issuance side-effects: tokens, keys, credentials, with expiry
- Public side-effects: publicly readable URLs, with TTL
- Money side-effects: charge, refund, transfer
- Trigger side-effects: async work enqueued in another system
If any answer is yes, the description must name it. Vague benefit language (“processes your request”) is not announce-intent. It is evasion. The discipline is borrowed directly from physical robotics (Pixar’s announce-then-act pattern, in animation since 1986) and from older stage craft (Stanislavski’s telegraphing, with a vaudeville lineage older still). When a robot moves toward a human, it announces intent before motion begins; the motion is the same, but the announcement is what makes it safe.
Tools that take side-effecting action need the same discipline. The 7-category enumeration is the static-spec version of the audit-trail receipt’s runtime record. Both halves are required. Receipt without announce-intent means the human only learns the full scope after committing. Announce-intent without receipt means the human trusts the announcement with no way to verify reality.
 The seven side-effect categories are the static-spec half (TYPES bookend); the audit-trail receipt is the runtime half (TESTS bookend). Spec declares, receipt verifies. Both halves are required.
The seven side-effect categories are the static-spec half (TYPES bookend); the audit-trail receipt is the runtime half (TESTS bookend). Spec declares, receipt verifies. Both halves are required.
How the multilayer kill switch maps onto the six checks
A real kill switch lives at more than one layer:
- Runtime cancel stops a runaway agent burning compute
- Identity revoke invalidates the credential after a breach is detected
- Gateway block intercepts a tool call before it executes
- Payment freeze stops a spend instrument from clearing
- Workflow interrupt stops the sequence before a sensitive node fires
A six-check audit-trail receipt is not the whole kill switch, but each check participates in at least one layer. Input validation and rate limit are workflow-interrupt layers. Daily cost ceiling is a spend-ceiling layer. CRM upsert and token mint participate in the identity-revoke layer (the contact can be deleted, the token can be expired). Fulfillment dispatch is the last-line-of-defense layer (Brevo can suspend the sender).
The point is not that the Reliability Kit ships every kill-switch layer. The point is that the Kit documents which layer each check participates in, so partners running on Cloudflare or AWS or Auth0 know exactly which of their existing layers our checks slot under. That is the difference between “we have safety features” and “we ship the observability layer of a multilayer kill switch your stack already partially has.”
Your stack plus our control point equals production-ready. Not “buy our methodology.” Your runtime, your identity, your data, your gateway, plus our receipt. The licensing motion lives in that sentence.
What this means if you are evaluating the Agent Reliability Kit for licensing
The architectural map is the message. The Kit sits on one of the five control points: observability. It does not compete with Cloudflare, AWS, Auth0, or Snowflake. It pairs with whichever of those four you have already chosen and adds the receipt.
That means:
- “We are not a Claude shop.” The Kit is protocol-neutral. The MCP storefront has produced identical receipts from hosted Claude AND from Qwen3.6 27B running fully offline. Your model choice is yours.
- “We already use Auth0 / Okta / Entra.” The Kit slots under your identity layer. The announce-intent-before-action discipline enumerates the side-effects your identity scopes need to enforce. A reference Auth0 integration sample lives at github.com/fabianwilliams/adotob-mcp/tree/main/samples/auth0.
- “We are on Cloudflare Agents / Bedrock AgentCore / Vercel.” The receipt format ports across runtimes. Only the storage-backend module changes (R2 instead of Azure Blob, etc.).
The licensing case is no longer “buy our methodology.” It is “close the observability debt on one row of the five-control-point table.” The other four rows stay your decision.
What this piece contributes
- A name for the gap most agent stacks ship with: supervision debt, the cumulative trust deficit between claimed and shipped controls.
- A concrete pattern that pays it down on the observability row: a public, consumer-readable audit-trail receipt URL plus a 7-category side-effect enumeration on every tool that produces it.
- A positioning shift: the Agent Reliability Kit is one control point, not a stack. Partners keep their runtime, identity, data, and gateway choices. They add the receipt. That is the entire pitch.
Cheers, Fabian Williams
If you are building agents for clients and the procurement-shaped questions in this post sound familiar, I would value a 20-min back-and-forth on where the patterns hold and where they break. The licensed (non-sanitized) Kit covers the worked examples this post sketches.
- Blog: fabswill.com
- Twitter/X: @fabianwilliams
- MCP storefront: mcp.adotob.com
- Agent Reliability Kit (OSS): agentic-engineering-toolkit
- Partner licensing: estore.adotob.com/partners
Agent Reliability Kit™ is a trademark of Adotob Solutions.
Credits: the five-control-points lens for partner conversations plus the multilayer-kill-switch idea were articulated by several writers during 2026, including Nate B Jones. The announce-intent discipline draws on physical-robotics design and stage-craft traditions (Pixar’s animation; Stanislavski’s telegraphing). The Auth0 AI Agents team for the delegated-authority-with-constraints pattern this piece references at the identity layer.