Qwen 3.6 vs gpt-oss:120b on M3 Max: I Ran a Harder Test, the 8× Speed Gap Surprised Me
I published a Qwen 3.6 vs gpt-oss migration story, then ran an un-gameable eval against both on the same M3 Max. The receipts changed the speed narrative — gpt-oss:120b ran 8 to 11 times faster than qwen3.6:27b at parity reasoning quality. Here is the methodology and the data.
TL;DR
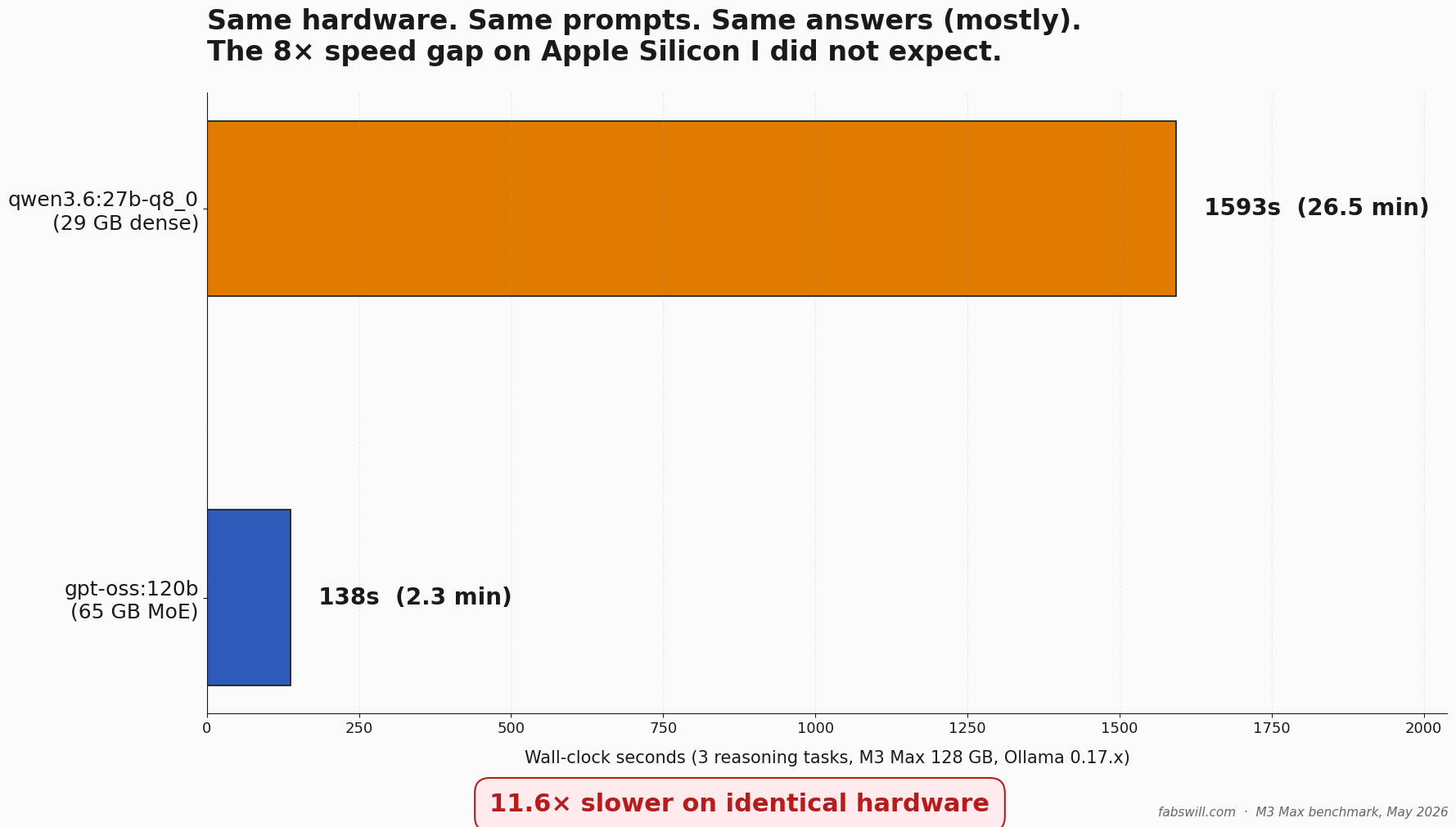
I published a post last week about replacing gpt-oss:120b with Qwen 3.6 on my MacBook Pro M3 Max. The numbers in that post were real, but one set of tests was structurally gameable — 38 of 40 baseline images were the same class, so an “always-say-A” stub also scored 95 percent. I went back, designed three un-gameable reasoning tasks, and ran them against both local models on identical hardware. gpt-oss:120b finished the three tasks in 137 seconds. qwen3.6:27b-q8_0 took 1593 seconds — 11.6 times slower, on the same M3 Max, for the same prompts and essentially the same answers. This post is the methodology, the receipts, and the honest correction to the migration narrative.
Operator priors should be tested, not trusted. The data is the data.
The Nag I Could Not Shake
The previous post said Qwen 3.6 was replacing gpt-oss in my workflow. The post had a chart showing speed wins on a coding-style benchmark and a multimodal capability test — both of those numbers were real. What it did not have was a clean head-to-head on structured editorial reasoning at production parameters.
I had also run an image-classification test against MACONA’s real nonprofit media library — 40 photos from a December 2025 computer-donation shipment to schools in Bamako, Mali, plus a February 2026 clothing donation. Both Qwen 3.6 and gpt-oss scored 40 out of 40 against gpt-4o’s earlier classification. That looked great.
Then I noticed something. 38 of the 40 images were Group A (computer-related) in the baseline. An “always-say-A” stub would also score 95 percent. The “100 percent agreement” headline was structurally meaningless — the test could not distinguish a thinking model from a constant function. I would have published that result. So I went back and designed a harder test.
The First Test Was Gameable. Here Is What That Means.
A gameable test is one where the data shape lets a stub pass. If 95 percent of your dataset is one class, an empty model that defaults to that class scores 95 percent — without doing any reasoning. The model looks competent. The benchmark is lying.
This happens more often than people admit. Class imbalance is normal. Most production datasets have a dominant class. If you measure agreement against a baseline that itself has the imbalance, your model can score high without actually being right for the right reasons.
The test for whether your benchmark is gameable: ask “could a stub that always picks the majority class pass this?” If yes, redesign before you publish numbers.
Both local models in Round 1 did correctly catch the two Group B clothing-sack images at positions 6 and 18. So they were not failing. But the 100 percent framing oversold what the test actually proved. The right framing is “models did not actively fail.” That is not nothing — but it is also not the headline the original chart implied.
Three Reasoning Tasks That Cannot Be Gamed
I designed Round 2 with three tasks. Each one is structured to block the always-majority trick.
T2 — Audience-aware curation. Pick exactly 5 photos for a fundraising landing page (audience: prospective donors). Pick 5 different photos for a donor thank-you email (audience: existing donors). The two sets must not overlap. Each pick gets a one-sentence rationale.
This forces the model to differentiate two audience needs from the same dataset. There is no majority class to default to. The right answer requires actual editorial reasoning about who is looking and why.
T3 — PII and compliance risk identification. Identify which photos warrant pre-publish PII review — identifiable faces of minors, background documents, ceremonial framing that might exploit subjects. It is OK to flag zero, few, or many. Each flag includes a specific concern.
This is needle-in-haystack. A constant function — “flag all” or “flag none” — fails immediately. The model has to actually look at each description and judge.
T4 — Thematic clustering. Group the 40 images into 3 to 5 thematic clusters, name each cluster, give a one-line description of what unifies it.
Open-ended structure-finding. No fixed ground truth. The metric becomes inter-model agreement plus a qualitative read of the rationales.
Same prompt, identical formatting, both models. Temperature 0.1, context window 8192, single-shot. Ollama HTTP API at localhost:11434/api/chat — about 30 lines of urllib.request. The simplest possible local-model integration.
What the Receipts Say
Here is what happened on identical hardware — MacBook Pro M3 Max, 128 GB unified memory, 40-core GPU, Ollama 0.17.x on Metal. Each model got one shot at each task.
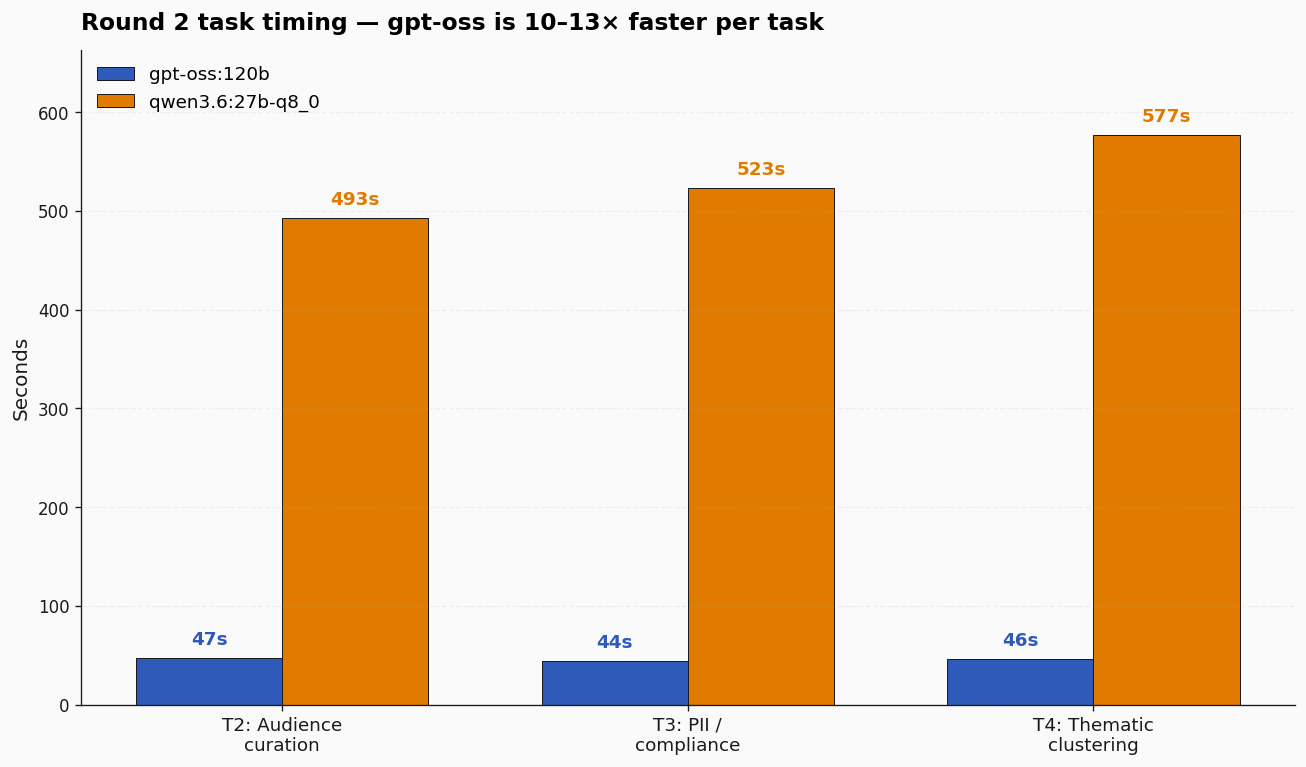
Per task: gpt-oss came in at 47, 44, and 46 seconds. Qwen 3.6 came in at 493, 523, and 577 seconds. The ratio is consistent — 10 to 13× per task. Total wall-clock for the three tasks: 137 seconds for gpt-oss, 1593 seconds for Qwen — 26.5 minutes versus 2.3 minutes.
This was not a cold-start artifact. I ran it warm and cold. The ratio holds.
The GPU was actually doing the work — not idling, not falling back to CPU. Here is the M3 Max GPU monitor during the eval, showing sustained 98 percent utilization on the active core cluster:
Closeup of the same monitor a minute later, with render and tiler utilization both at 60 percent — the kind of sustained pressure you only see when the model is genuinely chewing on a workload:
That is verification. Apple Silicon, Metal, real local inference. No cloud roundtrip.
Now the more interesting part — quality. If gpt-oss had been faster but wrong, the speed would not matter.
T3 was the strongest signal in the experiment. Both models flagged 25 of 40 photos for PII review. They agreed on 24 of those 25. Jaccard 0.92. Two completely different model lineages — gpt-oss is OpenAI-derived, Qwen is Alibaba-derived — independently produced essentially the same compliance profile.
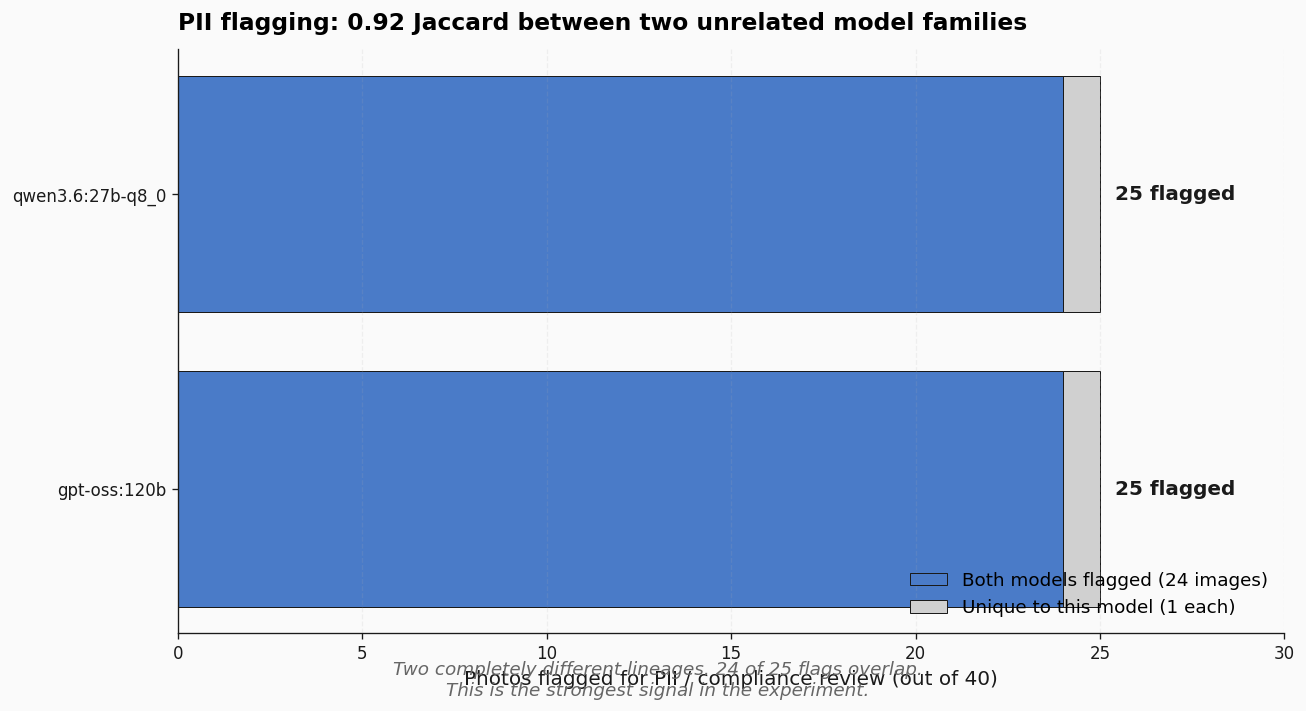
That kind of inter-family agreement is a stability signal you do not get for free. If you are considering a pre-publish PII gate using local models, this experiment says either model can carry it at production grade.
T2 — the audience-aware curation — surfaced something different. Both models picked 5 fundraising images. They overlapped on 4 of 5 (Jaccard 0.67). Then the same models picked 5 donor thank-you images and overlapped on only 1 of 5 (Jaccard 0.11).
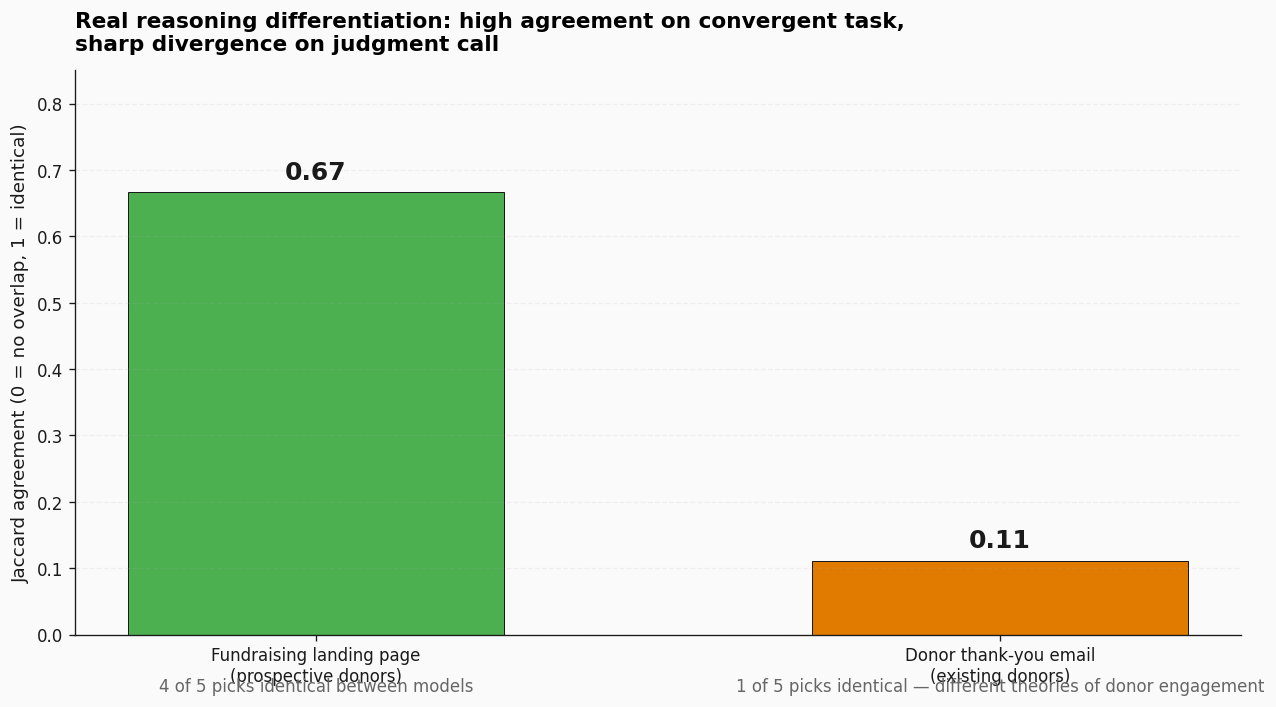
That is real reasoning differentiation surfacing. Both models converged on the impact-driven shots for fundraising — students using laptops, ceremonial handovers, clothing sacks at scale. Both models then diverged on thank-you, because thank-you is a judgment call. gpt-oss leaned classroom and event-prep — show donors where their money went. Qwen leaned process and inspection and clothing-as-loyalty signal — show donors the meticulous care behind every donation.
Neither answer is wrong. They reflect different theories of donor engagement. The benchmark surfaced where the models think alike and where they think differently — exactly what an honest eval should do.
T4 — the open-ended clustering — landed similarly. Both models identified the same two small clusters with identical membership: a “Computer Lab and Student Use” cluster (images 5, 24, 28, 37) and a “Clothing Donation” cluster (images 6, 18). Cluster names were nearly word-for-word the same. The structural difference was that Qwen split out a distinct “Group Portraits and Event Documentation” cluster of seven images; gpt-oss kept those inside a broader handover bucket. Qwen splits more, gpt-oss lumps more. Neither is wrong.
There is one more observation worth pulling out — from Round 1, the gameable round. When I asked each model to recommend headline photos for the blog post, gpt-4o picked 9 images (a varied mix). gpt-oss picked 2. Qwen picked 3.
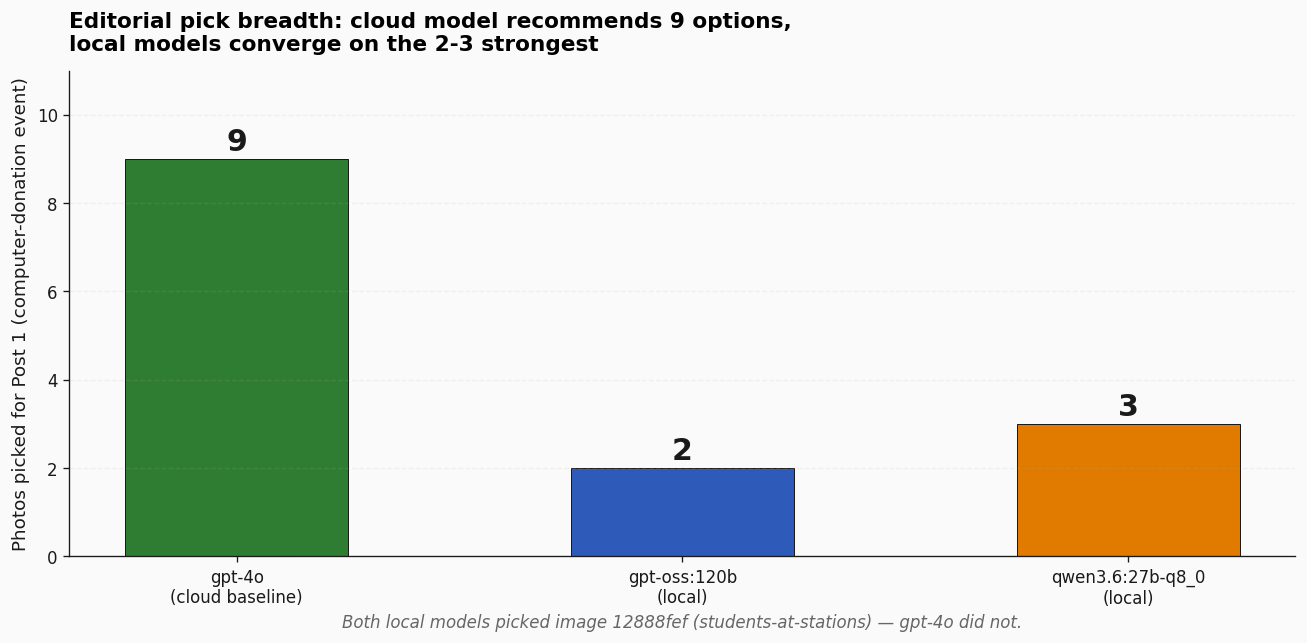
Both local models picked image 12888fef (students at desktop stations in a computer lab) — and gpt-4o did not pick that one at all. Arguably a stronger “show the impact” shot than several of gpt-4o’s choices. The local models converged on a narrower, more impact-focused selection.
That has a real implication for production pipelines. For an autonomous pipeline that picks ONE image without human review, the local conservative behavior is arguably better. For a human-in-loop where the editor wants choices, gpt-4o’s behavior wins. The right model depends on what the surface looks like — not just on which is “smarter.”
The Migration-Narrative Wrinkle
Going into the experiment, my prior was Qwen 3.6 is what I migrated to, so it should win on this workload. That prior was based on the previous post documenting the migration away from gpt-oss to Qwen 3.6.
The data did not support that prior on these tasks. On structured editorial reasoning — classification, audience curation, PII flagging, clustering — Qwen and gpt-oss are at parity in quality and gpt-oss is 8 to 11 times faster on the same hardware.
This does not mean the migration was a mistake. Qwen 3.6 may still win on dimensions this experiment did not test:
- Instruction-following on long-form prose — this test used short, structured prompts.
- Multilingual quality — this test was English-only.
- Code generation — especially the
qwen36-coding-strictandqwen3.6:35b-a3b-coding-nvfp4variants, which I have used elsewhere with strong results. - License terms — Qwen’s license may be a structural reason to prefer it for downstream products.
- Vision — Qwen has a strong vision lineage; this test was text-only over already-extracted descriptions.
- The
-strictguardrail variants — these behave differently and I did not test them in this run.
What this experiment does say is that on this specific class of structured-reasoning tasks at production-relevant prompt sizes, the speed story I told earlier was incomplete. The honest read is “Qwen ties on structured reasoning and is materially slower; the migration must have been justified by a different dimension.”
The original blog post needs an addendum. This post is that addendum.
Lessons I Am Carrying Forward
Always ask: can a majority-class stub pass this test? If yes, the test is gameable. Redesign before you publish numbers. The cost of catching it after publication is real — your audience trusts numbers more than you do.
Inter-model agreement is a useful proxy for tasks with no ground truth. When two unrelated model families independently produce 0.92 Jaccard on a 40-photo PII flag, that is a stability signal that would otherwise require human labelers. It is not a substitute for human judgment, but it is a usable floor.
Speed and quality tradeoffs are not always intuitive. A larger model can be faster than a smaller one on the same hardware. Cache state, MoE routing, and quantization all matter more than parameter count in isolation. Always measure on your actual workload — vendor benchmarks rarely match.
Operator priors should be tested, not trusted. My “Qwen will win” prior was the most interesting input to this experiment because the data invalidated it. That is the experiment doing its job. When you migrate models, design the eval that validates the migration before you switch — not after.
Preserve raw model outputs. Every
raw_*.txtfile from this experiment is preserved verbatim at/Users/fabswill/qwen-eval-march2026/. If a question comes up later about what the model actually said, the answer is on disk, not regenerated. Regenerated outputs can drift; saved outputs are receipts.The migration story matters more than the model choice. The data here does not say Qwen 3.6 is wrong. It says the narrative about why Qwen 3.6 is better needs to be honest about which dimensions actually matter for which use cases. Your model choices should be paired with similar receipts — both for your own decisions and for anyone reading your work.
Why This Matters Beyond My Setup
If you are running local models on Apple Silicon — or thinking about replacing a cloud reasoning step with a local one — the methodology in this post is portable. The dataset is private (real beneficiary photos at the input layer), but the runner scripts are about 30 lines each, the prompts are general, and the comparison metrics are turnkey.
The pattern is:
- Find a workload you currently run through a cloud model that produces structured output.
- Capture a baseline run — save the cloud model’s output verbatim.
- Build an un-gameable test design — make sure the task structure cannot be passed by a majority-class default. If the data is naturally imbalanced, augment with synthetic cases or change the framing to needle-in-haystack flagging.
- Run identical prompts on local models. Capture timing.
- Compute structured agreement metrics — Jaccard for set overlap, exact-match for label agreement, qualitative read for open-ended tasks.
- Document the migration-narrative wrinkle if it appears. Your prior may be wrong. The data is the data.
This is the pattern I am codifying into the next subfolder of the Agentic Engineering Toolkit: agent-receipt-patterns/local-vs-cloud-reasoning-eval/. A reproducible, cost-numbered, methodology-honest comparison of model outputs on a real production workload — the exact kind of artifact other practitioners running real fleets on consumer hardware are starving for.
The cost story is real. Round 1 plus Round 2, all local model calls: zero dollars at the API layer. The original gpt-4o vision pass that produced the descriptions cost about 34 cents in March. Total experiment cost — about 34 cents and electricity. Wall-clock time, including the writeup: roughly three hours. Compute time: about 50 minutes.
That is the argument for local-first architectures, in one line. Not “cloud is bad” — cloud is great when you need vision, frontier reasoning, or scale you cannot afford on-device. The argument is that for structured-reasoning steps inside a pipeline, the latency floor and the per-call cost are both negotiable on Apple Silicon. And once you start measuring, the model you thought was “the new one” might not be the one you actually want.
Cheers, Fabian Williams
I build autonomous AI agents and the tools to keep them honest. If you are running local models on Apple Silicon — or you have a Round 2 of your own where the receipts surprised you — I would like to hear what you are building.
- Blog: fabswill.com
- LinkedIn: fabiangwilliams
- Twitter/X: @fabianwilliams
- GitHub: agentic-engineering-toolkit