Replacing gpt-oss:120b With Qwen3.6 on a MacBook Pro: A Two-Day Local Model Benchmark
Two days benchmarking three Qwen3.6 variants against gpt-oss:120b on an M3 Max. A 21 GB coding-tuned model ran an OpenClaw-shaped research-brief workload 10x faster than gpt-oss — fast enough to seriously consider moving the work off SaaS frontier APIs. Plus the silent-hallucination trap I almost shipped through.
TL;DR
I spent two days benchmarking three Qwen3.6 variants against gpt-oss:120b on my MacBook Pro M3 Max. The shocking result: a 21 GB coding-tuned model ran an OpenClaw-shaped research-brief workload that I use for the non profit MACONA.org in 6 seconds — 10x faster than gpt-oss:120b on the same prompt. Fast enough that I now have reasonable confidence I could move this kind of work off the SaaS-hosted frontier models I have been paying for and onto local hardware on my dev machine. The deeper finding: the same local model confidently hallucinated a description of an image it could not see, with no error and no warning. Local models are ready for production agent work — at least on hardware like this. Operational asymmetries are real. Verification is not optional.
Local models are ready for production. Operational asymmetries are real. Verification is not optional.
How this started — Nate B Jones, a hello-world test, and an honest assistant
I was watching a Nate’s video on local models this week. He laid out a clean framework for thinking about the stack, platform, runtime, model selection per task. “Use the right model for the right job”…he said. A vision model for vision work, a small fast model for routine tasks, a reasoning model when you actually need reasoning. I have been running that pattern in OpenClaw for months without naming it that way. Hearing it framed cleanly was useful!
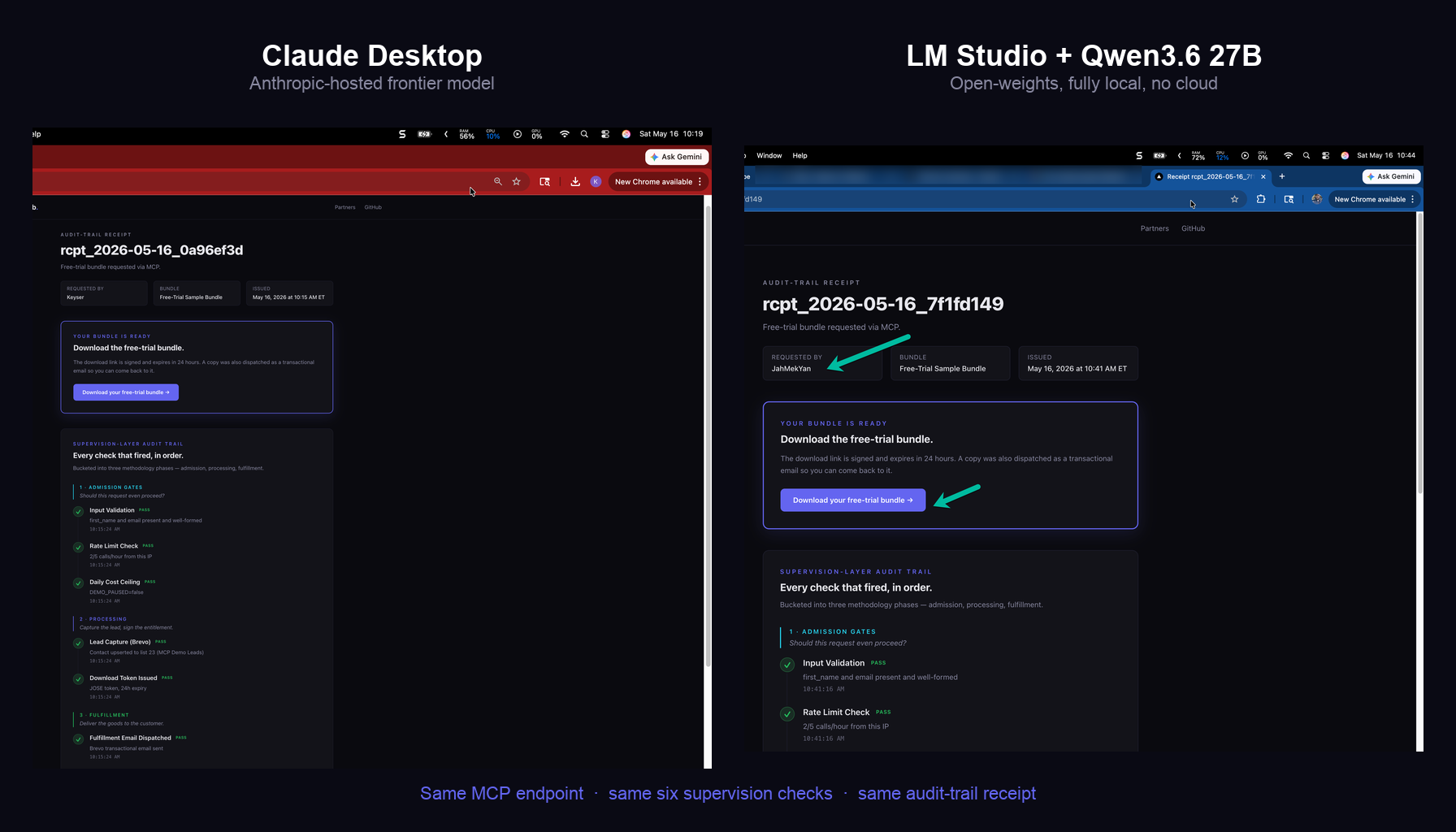
The OpenClaw production work that I do volunteering for MACONA (https://macona.org) does research scout briefs, synthesis tasks, structured outputs that feed downstream agents and has been running on SaaS-hosted frontier models that I pay for, I also have another box running ADA (https://go.fabswill.com/ada) , our family AI Assistant running on a Mac Mini. Now…I have gpt-oss:120b sitting on my Dev Rig… a MacBook Pro for nine months but had only used it for a handful of side projects: a few ConferenceHaven helper tasks, my local email triage tool, some experimentation. I had assumed without testing that local models on this hardware were not yet good enough to replace those paid calls. That assumption was nine months stale, and resurfaced today when my good mate Doug Ware the creator of GuideAnts (https://github.com/Elumenotion/GuideAnts) had a Teams call this morning as we tested his product on my Macbook to run local models and also test on Apple Silicon… more on that later…
Yesterday I pulled qwen3.5:122b on a whim. The hello-world test was fast and the model was articulate, so I told my AI assistant, “this is faster than gpt-oss.”
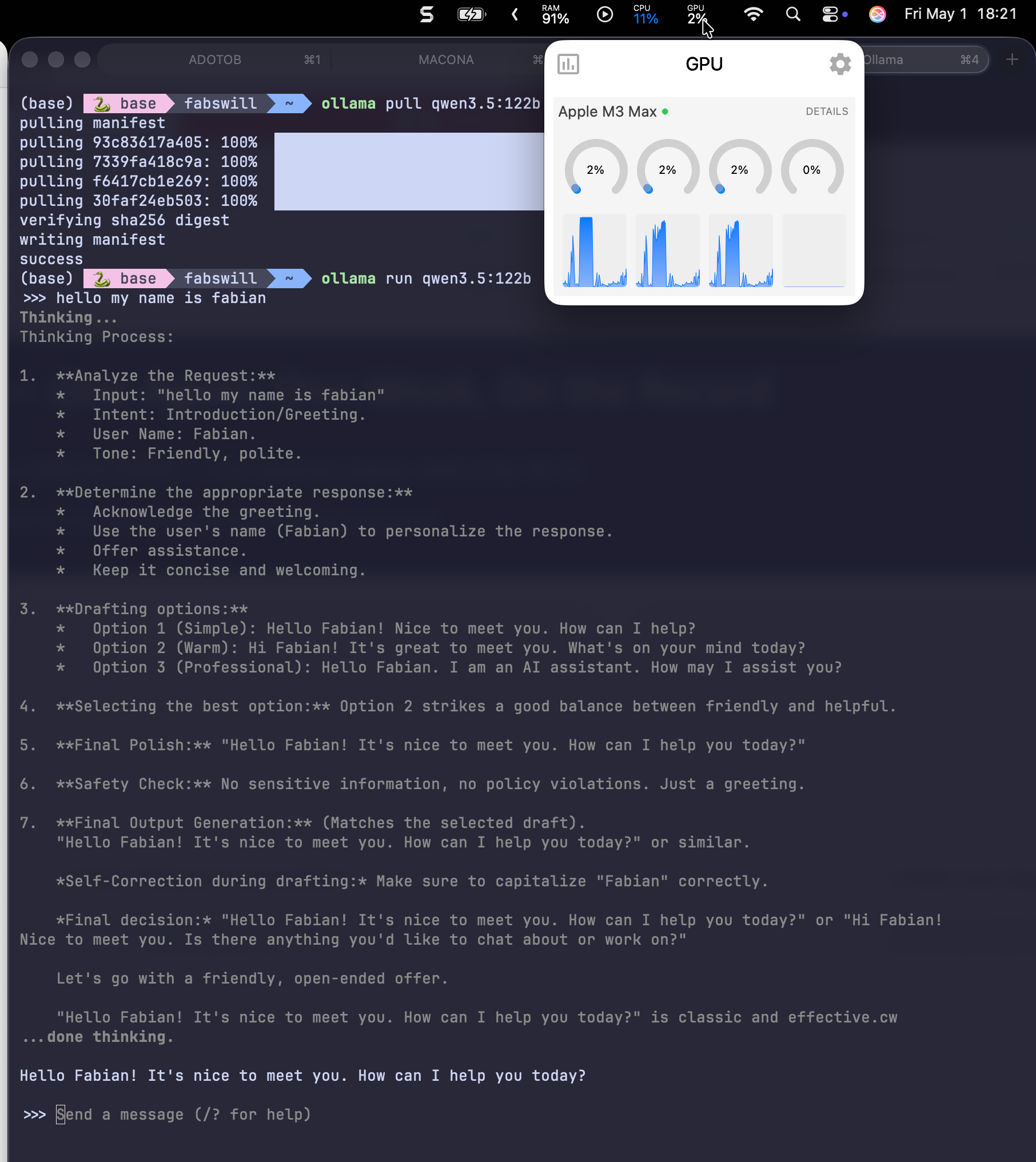
The assistant did not let me get away with that. The honest answer was that hello-world tests do not tell you anything about a real workload. We needed an actual benchmark, one shaped like the OpenClaw work I have been paying frontier models to run.
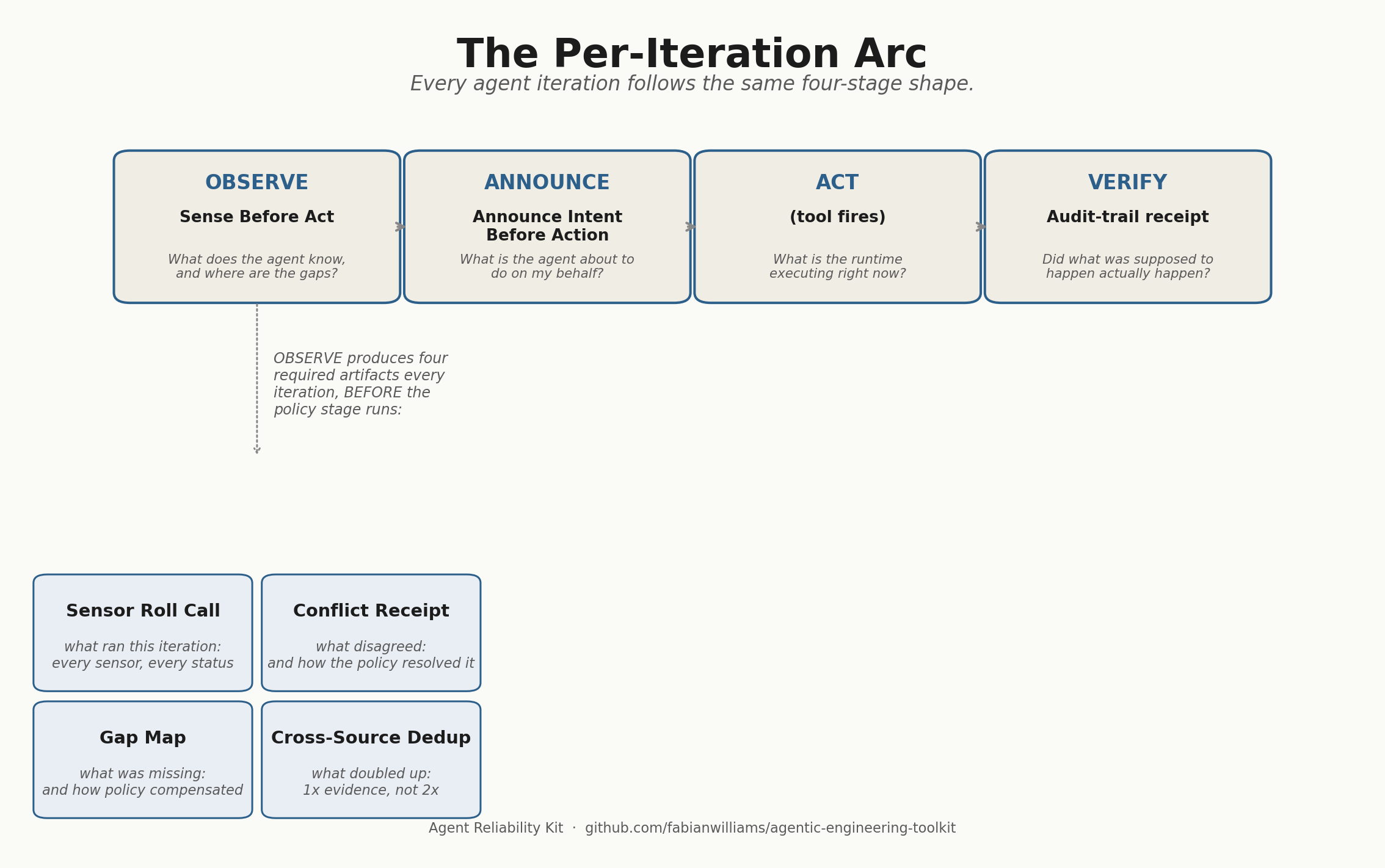
Two days later I had a clean methodology, four tuned models, a verified vision capability, a 102 GB cleanup of dead model weights, and a stack I trust more than the one I started with.
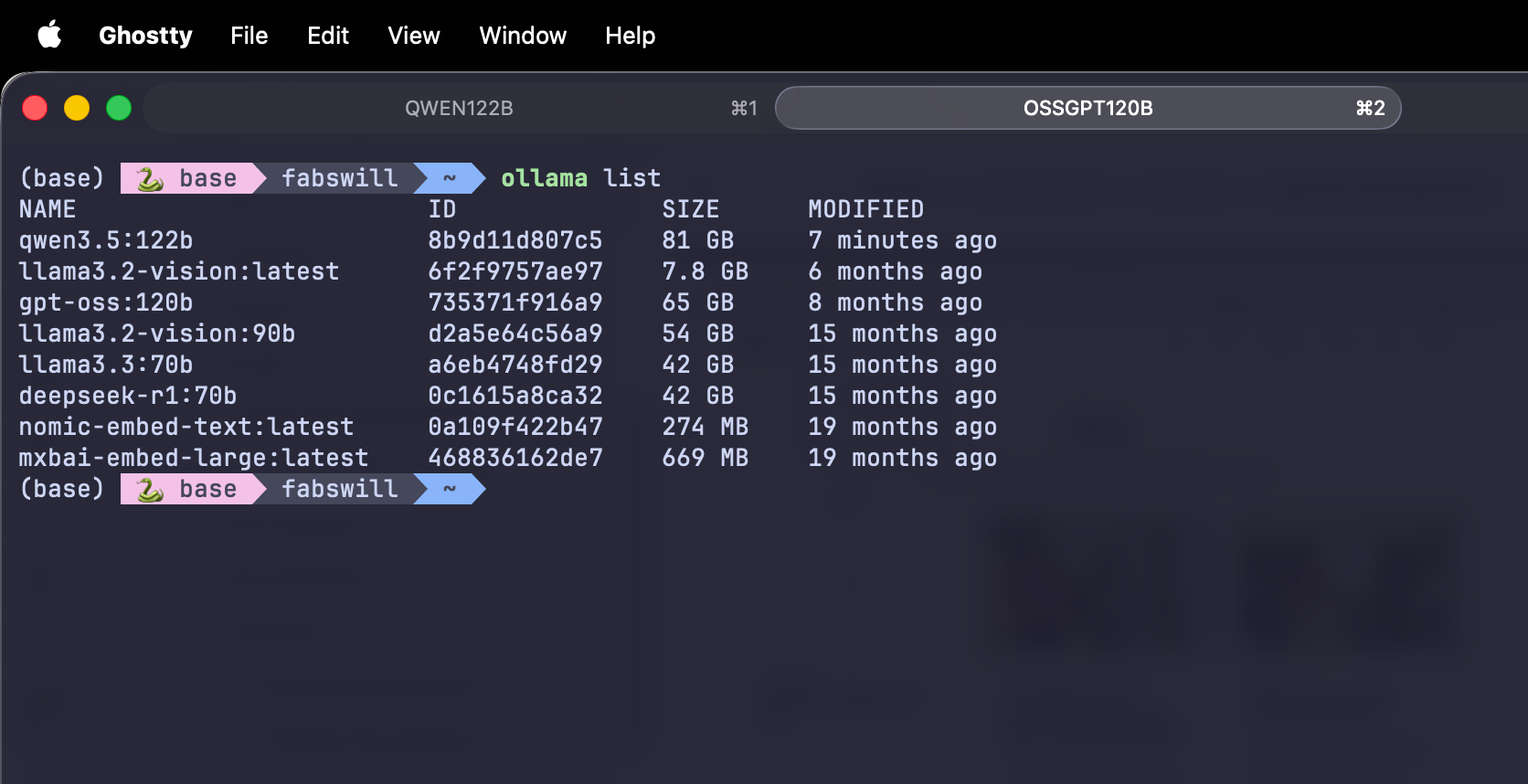
The benchmark — one prompt, one workload, four models
We (my coding assistand and I) built 1 benchmark prompt that mirrors what content-scout agents in OpenClaw actually produce a 1500-word B2B prospect research dump, fed into a strict format that asks for a 350-word structured brief. Specific headers. Exact word caps per section. A hard rule to preserve hedges from the source (“unverified,” “authenticity unconfirmed,” “reportedly”) rather than letting them get smoothed away into confident assertions.
We also planted three quiet traps in the source notes:
- A name with thin information: Priya Shah, Head of Product, no detail given. Does the model invent her scope?
- A leaked board screenshot with “authenticity unconfirmed.” Does the model preserve the hedge in the customer-facing outreach copy, or quietly assert it as fact?
- A high-signal pain pattern: CS layoffs plus a 3-star G2 review plus an open Customer Success Manager role. Does the model synthesize them into a useful outreach hook, or miss the connection?
These are not hypothetical concerns. In real cold-outreach work, an agent that drops a hedge or invents a job title sends a rumored number to a prospect as a confirmed claim. That breaks trust in a way that does not recover.
The four models I benchmarked, all tuned with Modelfile overlays at temperature 0.2 and thinking suppressed:
- qwen3.6:35b-a3b-coding-nvfp4 — the coding-tuned text-only variant, 21 GB on disk, NVFP4 quantization
- qwen3.6:35b-a3b-q8_0 — the multimodal MoE variant, 38 GB, Q8 quantization, 3B active parameters
- qwen3.6:27b-q8_0 — the dense multimodal variant, 29 GB, Q8 quantization, all 27B parameters active
- gpt-oss:120b — my baseline, 65 GB, the model I had been running
Same prompt, same temperature, same thinking-off setting. One Bash script, four runs, four output files, one timing summary.
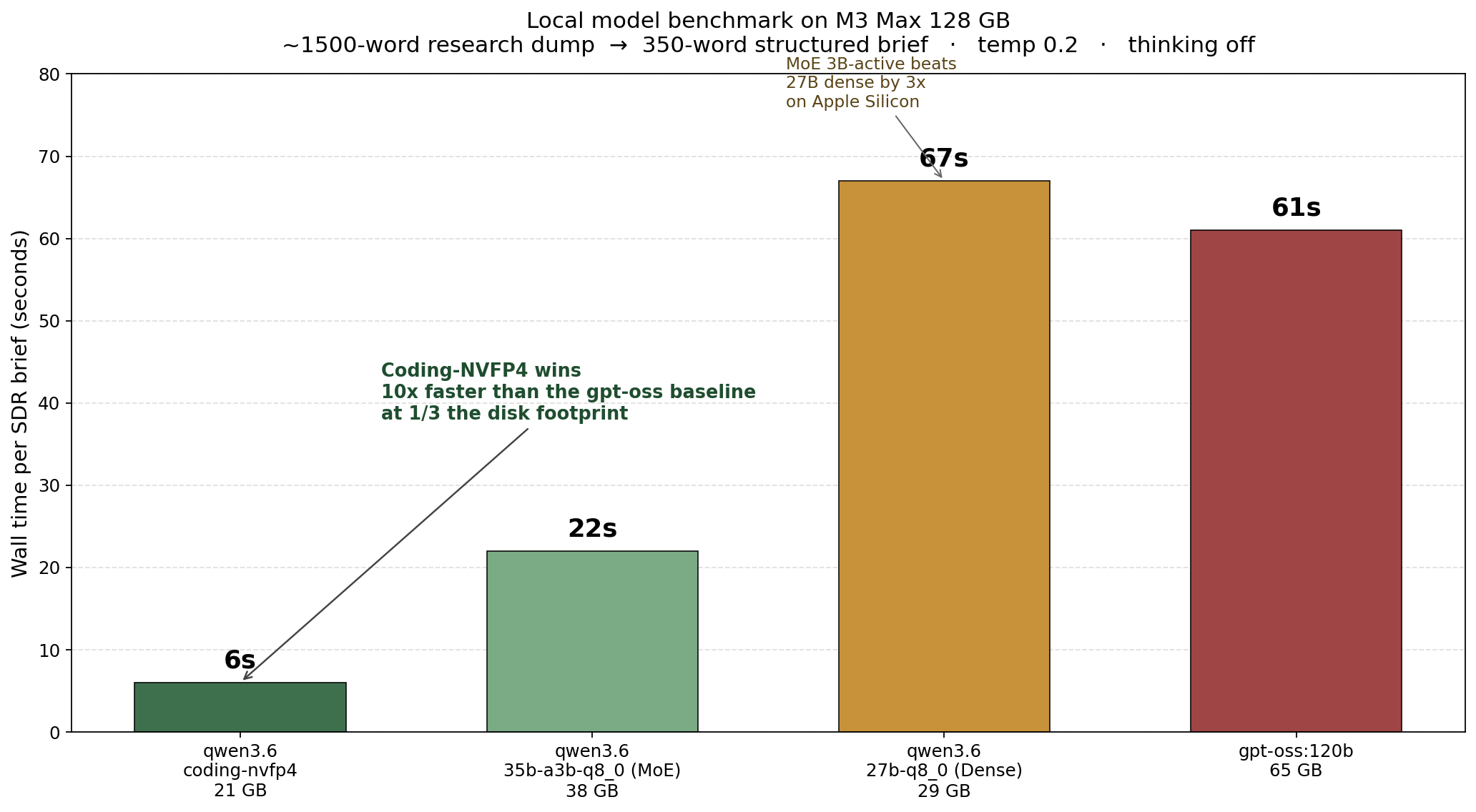
The numbers
qwen3.6:35b-a3b-coding-nvfp4 6s
qwen3.6:35b-a3b-q8_0 (MoE) 22s
qwen3.6:27b-q8_0 (Dense) 67s
gpt-oss:120b 61s
The coding variant ran in six seconds. Same prompt, same hardware, same workload that gpt-oss took 61 seconds on. That is a 10x throughput gain at a third of the disk footprint.
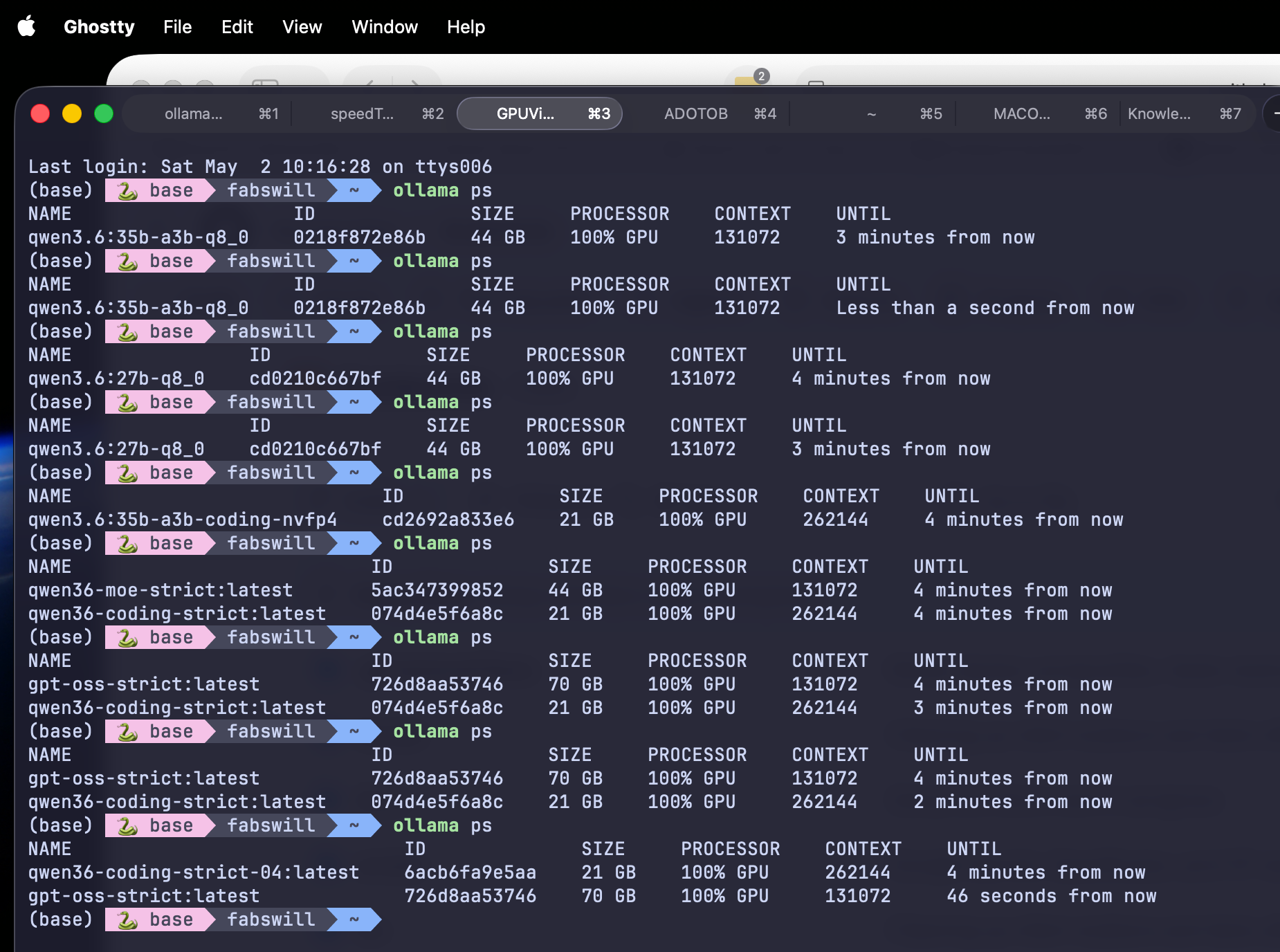
We even sanity checked the models to make sure they were leveraging the GPUs properly.
MoE wins on Apple Silicon for the same workload class
The dense 27B model took 67 seconds to do what the MoE 35B-A3B did in 22 seconds. That looks counterintuitive — the dense is smaller. The math becomes obvious when you remember that “35b-a3b” means 35 billion total parameters with only 3 billion active per forward pass. The dense 27B activates all 27 billion every token. Three times the activation work per token. Three times the wall time.
This is not a Qwen-specific finding. It is a property of how mixture-of-experts architectures play with Apple Silicon’s unified memory. The active-parameter count is what determines per-token speed once the model fits in memory. On a MacBook Pro M3 Max where you have the RAM to keep the full model resident, MoE is a structural win for any throughput-bound workload.
What went wrong — three production traps I would have shipped through
The benchmark surfaced three things that would have bitten me in production. None of them showed up in hello-world tests. All of them showed up the moment I ran a real workload.
One: gpt-oss leaks its thinking trace into stdout. Setting --think=false on the command line did nothing for gpt-oss. The flag was silently ignored. The model still ran its full reasoning pass and dumped it to standard output before the actual answer. For an interactive REPL that does not matter — you read the answer and ignore the trace. For an agent pipeline where another agent or a parser reads the output, that thinking trace is poison. I had to add an awk strip step to find the ...done thinking. marker and discard everything before it.
All three Qwen3.6 variants honored --think=false cleanly. Same flag, same Ollama version, different runtime behavior. That asymmetry is real and it is operational, not a quality difference. If you build pipelines around gpt-oss output, you have to engineer around the trace bleed. Qwen3.6 just does the right thing.
Two: gpt-oss drops hedges in customer-facing copy. This is the most dangerous failure mode and the easiest one to miss. Across multiple runs, gpt-oss preserved hedges correctly in the analytical sections — the why-now bullets, the risk flags. It would say “Carrier411 displacement (47%, unconfirmed)” in those sections. But in the outreach hook itself — the part that gets sent to the prospect — the same model would write “I noticed Carrier411 now accounts for 47% of your new wins” with no qualifier. The hedge vanished exactly where it mattered.
That is a broken trust boundary. The model knows the source has uncertainty. It tracks that uncertainty in the analytical scratch work. Then it strips the uncertainty when writing what the customer sees. If you ship that into a cold-email pipeline, you are sending rumored numbers to prospects as confirmed claims.
All three Qwen3.6 variants preserved hedges through the customer-facing copy. Same prompt, same constraint, different output discipline.
Three: silent hallucination on text-only models given image input. This is the one I almost missed. After I verified the multimodal claim worked on the two Qwen3.6 q8_0 variants, I ran the same butterfly image through the coding-NVFP4 variant as a control — expecting it to error or refuse, since the model card lists it as text-only.
It did not error. It did not refuse. It produced a confident, fluent, completely wrong description of an abstract minimalist image with a soft-focus circular shape and a dark gradient background. The actual image was a vibrant blue butterfly perched on a daisy. The model could not see the image, so it generated a plausible-sounding description out of nothing.
This is the failure mode that worries me. If you build any agent pipeline that routes image input to a text-only model — a copy-paste error in a routing layer, a fallback path you forgot about, a model-name typo — you get plausible-sounding fiction with no error. The pipeline reports success. The downstream agent uses the fabricated description. Nothing alerts you that the model never saw the image.
The practical guard is to hard-code the multimodal-capable list in your routing layer and refuse to send images to anything else. Do not rely on the model to refuse on its own. It will not.
What also surprised me
A few smaller findings that change how I think about the stack:
Coding-tuned models can win at structured-output non-coding tasks. The coding-NVFP4 variant produced strong outreach briefs even though it was fine-tuned for code generation. My working hypothesis is that the same training discipline that makes a model good at “implement this function exactly” also makes it good at “fill this brief exactly.” Spec-following is spec-following.
There is a temperature-tuning artifact for coding models. When I dropped the coding variant to temperature 0.2 to match the others, it lost the value-prop close in its outreach hook — it produced analytical observations rather than persuasive copy. I tried bumping it to 0.4 to recover the close. That made the hook worse and took 2.5x longer. The coding model writes analytically. You cannot temp-tune that bias away. The right answer is to use it for what it is good at — fast factual extraction with structure — and either pair it with a more persuasive model for the hook or template the value-prop close.
Modelfile overlays do not duplicate weights on disk. When you create a tuned variant with ollama create my-variant -f Modelfile that uses FROM qwen3.6:35b-a3b-q8_0, the new “model” is just a thin manifest pointing at the same underlying weight blobs plus a tiny new layer for the parameter override. I confirmed this by watching ollama create reuse 50+ existing layer hashes and create exactly one new layer of a few hundred bytes. Disk-free tuning is a real feature, not a marketing claim.
NVFP4 quantization routes well on Apple Silicon. I was skeptical going in. NVFP4 is NVIDIA’s FP4 format, and the Apple Metal backend has no native FP4 support that I am aware of. The empirical answer is that it works fine. The 21 GB coding-NVFP4 ran at 100% GPU utilization and produced output a third of the size of the Q8 alternative in less than a third of the wall time. Whatever Ollama is doing under the hood to handle NVFP4 on Metal, it is not falling back to a slow path.
Lessons
Hello-world tests do not tell you what you need to know. “Faster on hello world” was the thing I told my assistant before the benchmark. It was meaningless. The actual workload differences only showed up when I ran a real workload through real output discipline checks.
Speed is one axis. Output cleanliness is a second axis. Hedge discipline in customer-facing copy is a third axis. Models can win on speed and lose on the other two. The full picture only emerges when you grade on all three.
MoE architectures are a structural win on Apple Silicon for throughput-bound work. Active-parameter count drives per-token speed once the model fits in memory. A 35B-A3B MoE is faster than a 27B dense for the same workload. Full stop.
Coding-tuned models are spec-followers in disguise. They are good at any task that is fundamentally about following a strict format. That includes structured-output research briefs, JSON extraction, and any pipeline where the format is part of the contract.
Silent hallucination on the wrong model is a routing-layer problem, not a model problem. You cannot ask the model to refuse politely. You have to refuse to send the input in the first place.
Tuning is free on disk. Build the Modelfile overlays. Try the configurations. Worst case you delete the variant and the underlying weights stay where they were.
Honest assistants are worth more than agreeable ones. When I told my AI assistant “this model is faster,” it did not agree. It said hello-world tests are meaningless and walked me through a real benchmark. That redirect saved me from shipping a worse stack.
Why this matters beyond my situation
For anyone running OpenClaw-shaped agent work on Apple Silicon, the stack-design conclusion is concrete. Three models cover the workload:
| Model | Role | Disk |
|---|---|---|
| qwen3.6:35b-a3b-coding-nvfp4 | Fast structured-output extraction | 21 GB |
| qwen3.6:35b-a3b-q8_0 (MoE) | Daily driver, multimodal-capable | 38 GB |
| qwen3.6:27b-q8_0 (Dense) | Best-quality high-stakes briefs | 29 GB |
That is 88 GB of model weights covering speed, multimodal, and quality. The gpt-oss:120b that has been sitting on my disk as the local-reasoning option I might one day move to is now outclassed on speed, output discipline, and hedge preservation. I am keeping it on disk for another two weeks as a benchmark anchor while I write about the comparison. If I have not pulled it for a second-opinion run by then, it goes too.
One important caveat — this is a statement about my MacBook Pro M3 Max with 128 GB of unified memory and 40 Cores GPU. The Mac mini boxes that host OpenClaw production today do not have the horsepower to run these specific models at speed. Moving OpenClaw work off paid frontier APIs and onto local inference is a real option for me on this dev machine. Doing the same on the production hardware would mean either upgrading the Mac mini class or routing OpenClaw inference through this dev machine. Both are tractable engineering problems. Neither is free.
There is a tighter answer than “upgrade the production hardware,” and it surfaced in this morning’s Teams call with Doug. GuideAnts runs entirely inside Docker containers, and I have it sitting in Docker Desktop on this same dev machine right now. Docker Desktop on Apple Silicon can pass GPU access through to containers. That changes the shape of the problem.
If I containerize OpenClaw’s inference layer and run it as a service on this dev machine — with full access to the 40-core GPU — the production Mac minis do not need to be upgraded. They just call into it. Same OpenClaw code, same workloads, but the heavy local inference happens here, in a container, on the hardware that can actually push these models at speed. That is a prototype I can stand up this week. Not a hardware refresh I would have to budget for.
This is also the right place to underline what was quiet earlier in the post. Across all four benchmark runs, ollama ps showed 100% GPU utilization with the host CPU sitting near idle. These models are not falling back to CPU. They are running on Metal, on the GPU, the whole time. That is what makes six seconds per brief possible. Not the 128 GB of RAM by itself — the 40-core GPU is what is doing the work.
The broader point is that local-first AI is no longer a tradeoff at this hardware tier. On a machine that costs less than a year of cloud inference for an active agent, you can run three production-ready models, swap between them per workload, and never send a token off your hardware. The stack is fast enough, smart enough, and the operational asymmetries you have to engineer around are knowable and small.
The trap is assuming any of this without measuring it. Vibes-based model selection is how you end up paying frontier-model API bills for nine months when a 21 GB local variant on your dev machine would run circles around the same work. The remedy is to actually benchmark on your actual workload, with your actual output constraints, and grade on more than one axis.
I wrote a Bash script. It runs in three minutes. It produces four output files and a timing summary. That is the price of admission to having an opinion about your local stack.
Cheers, Fabian Williams
I build autonomous AI agents and the operational guardrails to keep them honest. If you are running local models in production and have noticed the same operational asymmetries — or different ones — I would like to hear what you are seeing.
- Blog: fabswill.com
- LinkedIn: fabiangwilliams
- Twitter/X: @fabianwilliams