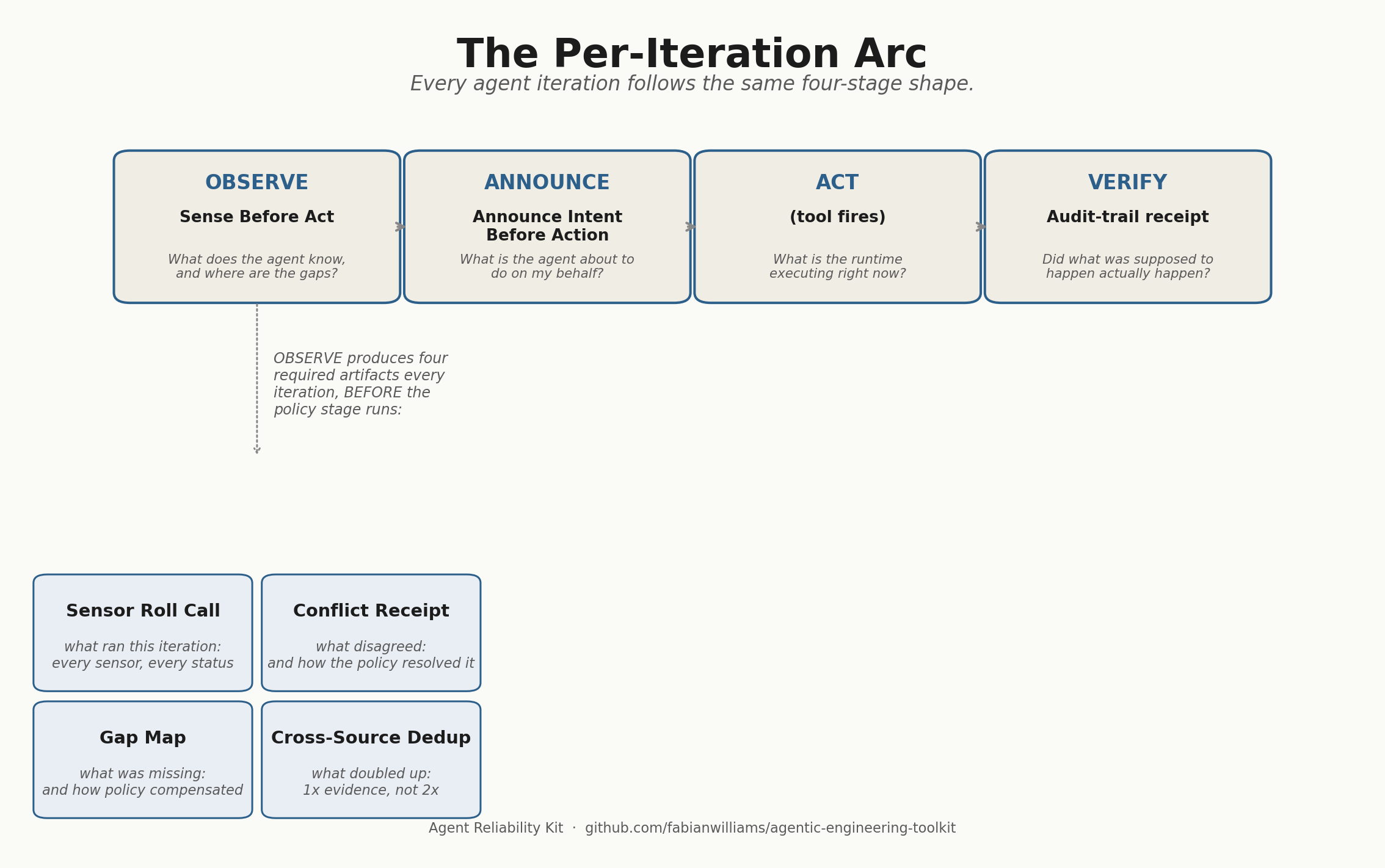
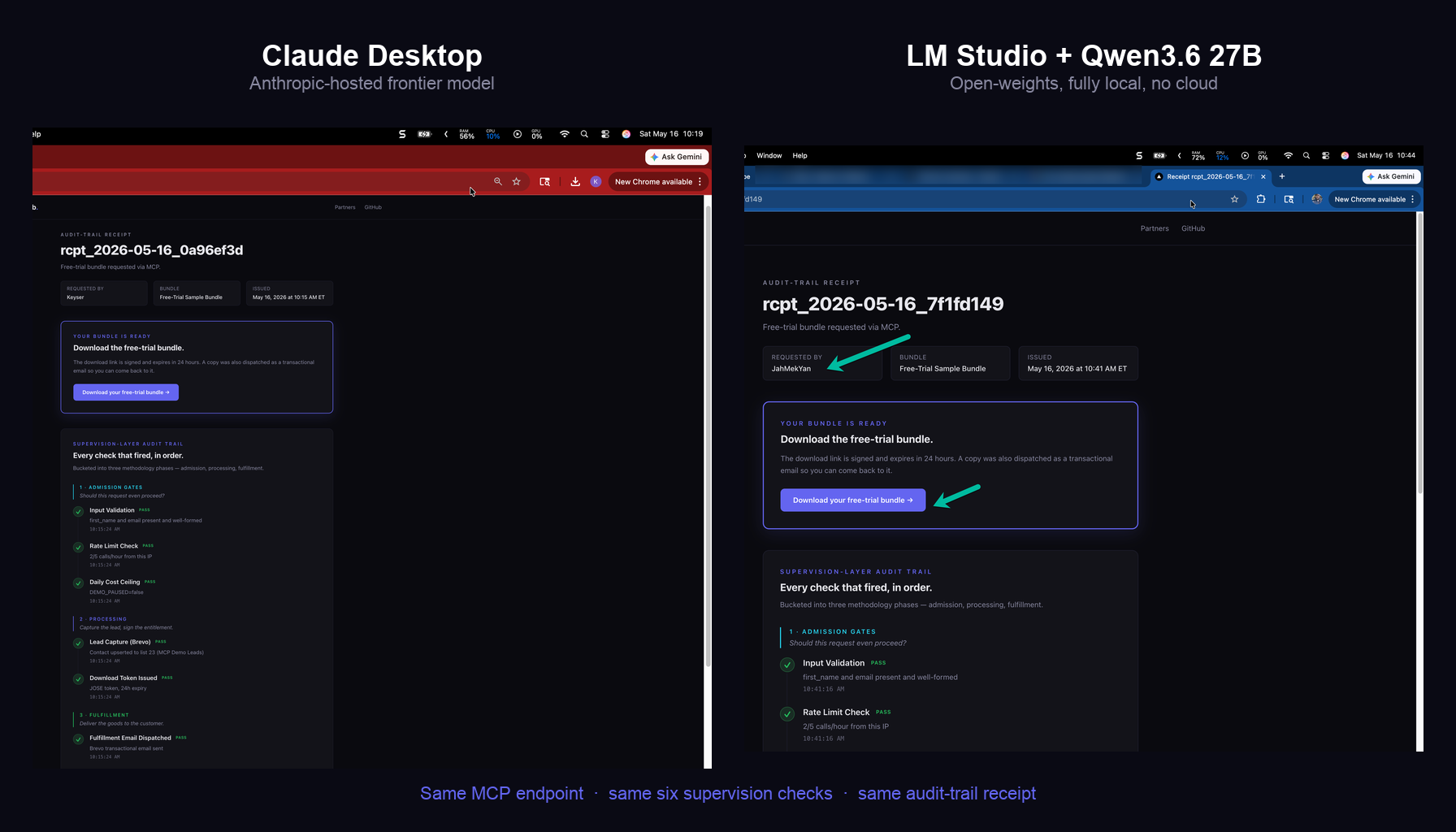
Replacing gpt-oss:120b With Qwen3.6 on a MacBook Pro: A Two-Day Local Model Benchmark
Two days benchmarking three Qwen3.6 variants against gpt-oss:120b on an M3 Max. A 21 GB coding-tuned model ran an OpenClaw-shaped research-brief workload 10x faster than gpt-oss — fast enough to seriously consider moving the work off SaaS frontier APIs. Plus the silent-hallucination trap I almost shipped through.
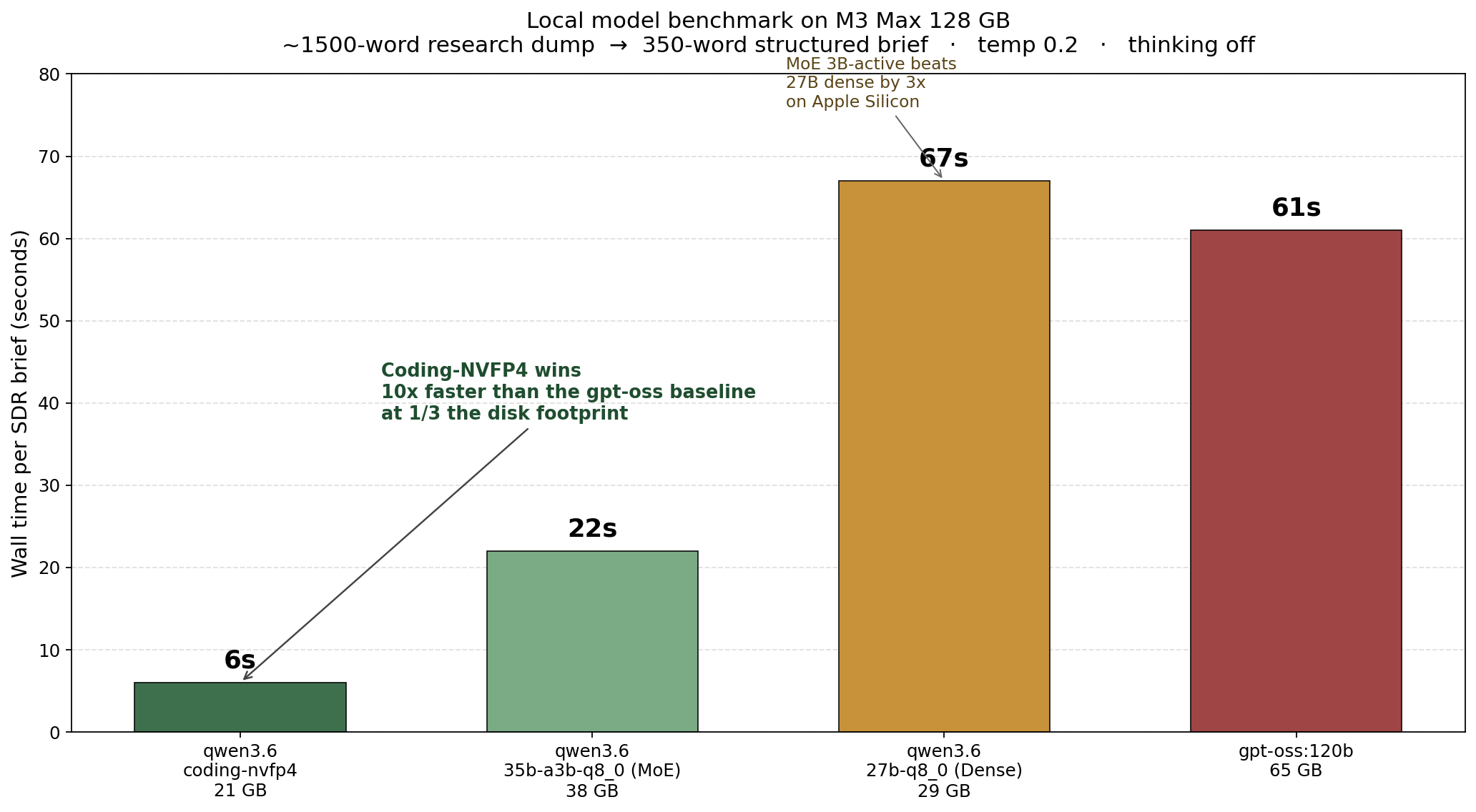
I spent two days benchmarking three Qwen3.6 variants against gpt-oss:120b on my MacBook Pro M3 Max. The shocking result: a 21 GB coding-tuned model ran an OpenClaw-shaped research-brief workload that I use for the non profit MACONA.org in 6 seconds — 10x faster than gpt-oss:120b on the same prompt. Fast enough that I now have reasonable confidence I could move this kind of work off the SaaS-hosted frontier models I have been paying for and onto local hardware on my dev machine. The deeper…