The AI Agent Fleet Works. The Trust Funnel Does Not.
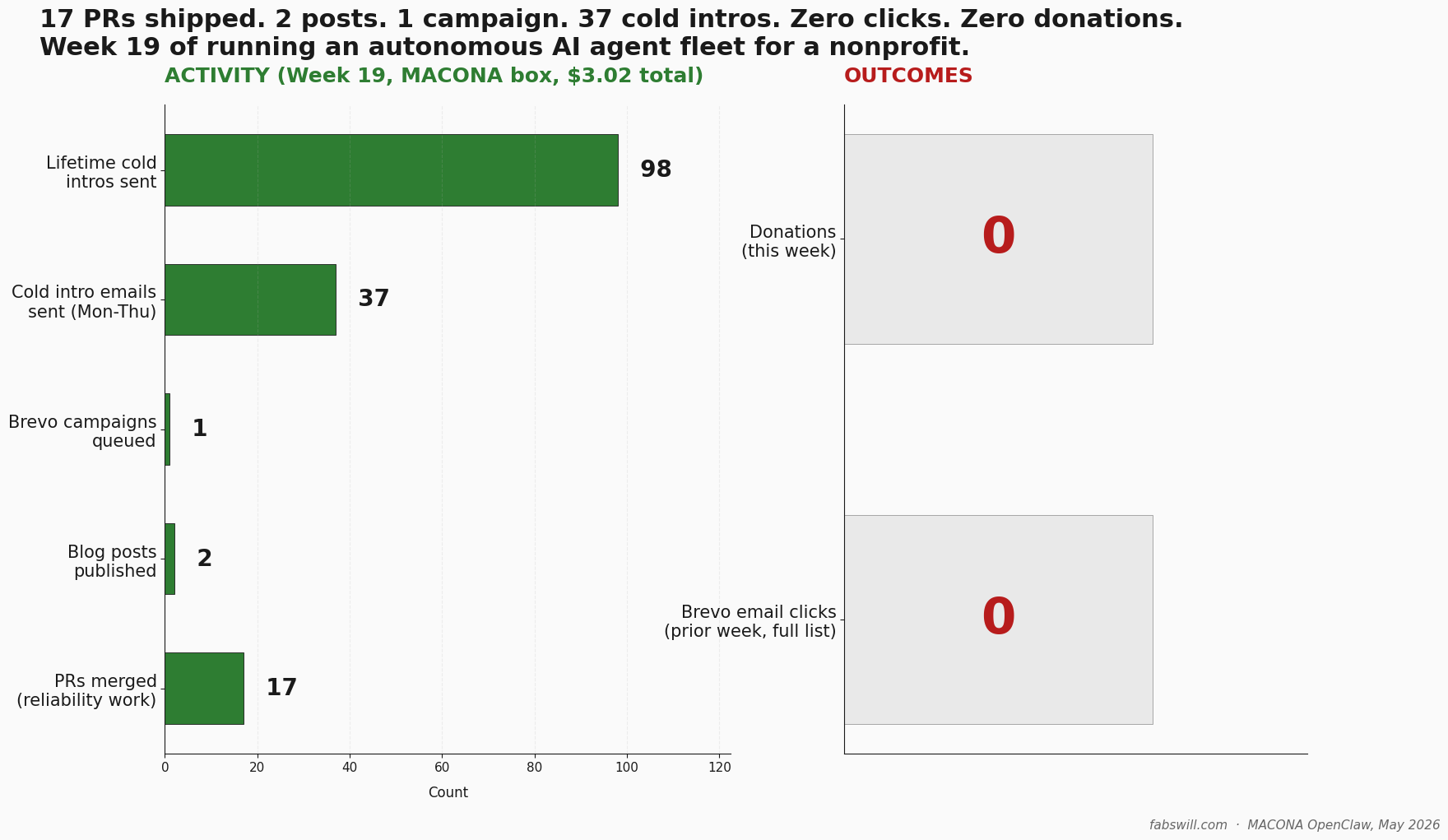
A small autonomous AI agent fleet I run as a volunteer for a 501(c)(3) nonprofit. Week 19 shipped 17 reliability PRs, 2 awareness-day blog posts, and 37 cold introductions — and earned zero human clicks, zero donations. This is the corrections panel I wrote on my own retro before anyone else could.
I volunteer with MACONA, a 501©(3) nonprofit that ships food, medicine, feminine hygiene products, donated computers, and clothing to communities and schools in West Africa. For a few few monthis now I have run a small autonomous AI agent fleet for the organization: five named agents, cron-driven, running through OpenClaw on a simple Windows box.